For financial services organizations looking to move their applications into AWS, not knowing the true resiliency of those applications, and the infrastructure behind them presents a great risk. Most businesses try to adhere to industry best practices in regards to architecting their AWS environments in a way that is highly available, scalable, and fault-tolerant but there is no avoiding the inevitable failures and disruptions in those environments now and then. With hosting business-critical applications on AWS, businesses need to have a reliable testing strategy framework in place that regularly tests the resiliency of their AWS infrastructure.
As a financial services organization, there are many scenarios that would be very detrimental to the business and could potentially result in loss of productivity, losing customers, restricting incoming revenue, and even incurring legal penalties. Some of these scenarios may include:
- Latency in your order routing system causes delays in filling orders. The market moves rapidly and you have to fill the late orders at a disadvantageous price.
- Your market data system suffers an outage and fails to provide the latest pricing data. Your critical systems continue to process transactions with stale prices.
- An overnight batch processing system goes down. The system is unable to recover and books are not updated by the start of the next business day.
- One of your applications fails over to your Disaster Recovery region. Your other applications remain in the Primary region and are unable to connect to the one that failed over to DR.
A misconfigured Identity and Access Management (IAM) policy gives hackers access to your confidential documents, data, and financial reports.
There are often many applications within a financial services organization. Many of these applications may have been “lifted and shifted” into the cloud and are already running on AWS. In many cases, applications like these may not be architected to take full advantage of the resiliency capabilities that are possible within AWS. For these applications, and the ones that haven’t made their way to a live production environment, going through the process of performing a thorough resiliency assessment is critical.
Another item to consider is the availability prioritization of applications. Businesses need to identify which applications/products are mission-critical and what the up-time requirements are for those applications. There may be some applications that have an acceptable period of downtime but for other applications there may be the business expectation that they never see downtime. For these types of mission-critical applications, prioritizing resiliency assessment and testing against them is imperative. For example, some leading companies have adopted the following recovery targets for certain tiers of applications/systems:
- Critical systems (e.g. trading, order management, financial advisor desktop) – zero downtime except in the case of a regional failure and no data loss.
- Middle office systems (e.g. risk, treasury, performance) – Less than 15 minutes downtime except in the case of regional failure. Less than 5 minutes of data loss.
- Back office systems (e.g. settlements, reconciliation, accounting) – Less than one-hour downtime. All processes must pick up where they left off and complete before the start of the next business day
Without a reliable resiliency testing strategy in place, a business may lose valuable insight into critical areas including:
- How well their applications and supporting infrastructures can handle unexpected failure incidents and other negative scenarios.
- The reliability of their monitoring and alerting mechanisms and how quickly incident response teams are notified in the event of unexpected failures.
- An understanding of how knowledgeable and efficient incident response teams are when responding to and resolving unexpected failure.
By implementing a solid resiliency testing framework strategy within AWS, businesses can start to gain a better understanding of where they stand within their AWS environment. Some of the business benefits that can be gained include:
- A better understanding of how well applications perform in the event of unexpected failures within AWS and how that performance translates to business/market value.
- How resilient the infrastructure behind an application. This means that in the event of unexpected failures, are applications able to remain up without suffering downtime which results in loss of revenue. If applications do go down, then at least businesses can have an understanding of the length of time they can expect when that occurs.
- Confidence, gained through vetted resiliency testing, in a business’s AWS cloud environment before making the decision to deploy their applications/products to a live consumer market.
- A well built resiliency testing strategy framework in place that can be used/applied to future organizational teams and applications being developed in AWS.
“The most important thing to remember is that it is never too early to start thinking about resiliency.“
At a high level, a financial services organization may in one or multiple of these categories, in regards to their maturity in AWS, and it is recommended to consider these guidelines:
- If a business is just starting out on AWS, it is recommended to conduct an initial assessment that provides the following:
- A view of the technology infrastructure as a whole.
- A view of the business’s information architecture and the flow of data throughout its systems.
- A cloud feasibility assessment and deployment project plan.
- If a business is preparing to live to production with its cloud application, it is recommended to conduct a thorough resiliency assessment and gap analysis that covers the following:
- The business’s cloud architecture as a whole.
- Any critical dependencies.
- Business architecture diagrams.
- Failure mode effect analysis.
- Resiliency test scenarios and test cases.
- Resiliency test execution.
- If a business already has a mature set of cloud applications that are already deployed to production, it is recommended to perform the following:
- integrate resiliency testing as part of your CI/CD process in a lower environment that closely mimics productions. Performing resiliency testing in a pre-production environment will help to provide accurate data in how resilient those cloud applications will be in the event of failure when deployed into the live production environment.
- Use different forms of chaos engineering and failure injection methods in that pre-production environment to build confidence in the application’s capability to withstand unexpected failures in production.
Phase 1 – Initial Meetings and Information Gathering
Beginning the route for implementing a resilience assessment and testing framework can be overwhelming especially when dealing with enterprise-size businesses and all of the applications that are spread across the organization. Because of this, it is crucial to start off this assessment by gathering the foundational information required to be successful throughout this multi-step process. Some action items to accomplish during Phase 1 of the assessment should include:
- Choosing a centralized information/issue tracking tool to keep track of applications, test case details, and points-of-contact per application.
- Meetings with application team lead and project managers to determine and record the main points-of-contact per application. Recording this information allows for quickly figuring out who to contact when roadblocks occur during resiliency assessment and test execution.
- Meetings with project managers and stakeholders to establish the timeline and prioritization of resiliency assessment and test case execution.
- This is critical in determining the order in which certain applications are to be assessed and tested. Generally, it would be recommended to work towards prioritizing applications/products that are business mission-critical and/or are crucial in generating revenue.
Phase 2 – Deep Dive and Discovery
After the initial information gathering, we should begin to take a deep dive into the different cloud infrastructures and suite of applications being hosted on them. For this phase in a resiliency assessment, we should look to the different units within an organization, and the application teams with them, for technical information about the design, infrastructure, and components used within those applications. The goal for this phase would be to gain as much knowledge and understanding of the applications as possible. Some recommended areas to pursue would include:
- Gathering any technical diagrams that show the infrastructure behind the applications and the flow of data/information.
- Knowledge of the different AWS services being used for the applications and how they have been implemented.
- Any documentation that explains the different purposes, use cases, and expected behaviors of applications.
- An understanding of the network flow between applications and any other services in which they communicate with.
- Any external dependencies and tools being used with the applications.
The information gathered here should be organized by application and stored in a centralized location so that it can be easily retrieved and referenced. This information will play a critical role when we get to the actual creation of the resiliency test cases.
Phase 3 – Generating the Test Cases
For the third phase, we should begin the creation of the resiliency test cases that will eventually be executed in a pre-production environment. This would entail using the data we’ve gathered about the applications to craft a combination of both automated and manual tests that are separated into unique categories.
“The purpose of these test cases is to simulate failure through predefined injection methods”
For each application that will be tested against for its resiliency, we should begin to formulate specific test cases that will simulate failure against the unique components and functionality of the applications. Each resiliency test case should be detailed and organized to contain clear-cut information about the test case, what it does, and the expected outcome. Below is a sample chart of information that could be part of a single test case.
| Application/ID | Unique ID of the test case with the name of its associated application |
| Category | Category of the type of resiliency test case |
| Scenario | The scenario of failure that is being introduced and injected as a simulation |
| Description | A description of the test case and the scenario that provides more detailed information about what happens during the execution of the test case |
| AWS Service(s) | The AWS service(s) that are involved in the execution of the test case that will be affected by failure injection |
| Application Components | The components of the application that are involved and expected to be affected during the execution of the test case |
| Tools/Utilities Used | Any tools, utilities, or scripts that are being used to perform the injection of failure |
| Expected Outcome | The expected outcome of the test case after the injection of failure has occurred |
| Execution Steps | The specific steps required to perform the test case and introduce failure into the application and/or its infrastructure components |
| Actual Results | The actual results that occurred as a result of performing the test case |
| Status | The status of execution of the test case |
Figure-01
The information created as part of the test case should be stored and organized in the centralized location for tracking the resiliency assessment of the organization’s applications.
“Ideally, resiliency test cases should be crafted with the goal of being reusable and repeatable across many applications and systems”
In many situations, resiliency test cases may have some overlap between multiple different applications. There may be certain types of failure injection methods that can be applied to many different applications and so, as such, they should be created in a way where the team responsible for performing the resiliency test executions can easily reuse them wherever they may be applied. This also goes hand-in-hand with keeping the details of these cases uniformed, consistent, and organized. By creating test cases in such a way, we are able to easily reference similar scenarios that may occur to different types of applications and apply the same methods of failure injection to perform those test case executions.
Phase 4 – Scheduling of Test Execution
The final phase of this resiliency assessment and test case execution would be the planning of test execution dates/times. This would just involve forecasting out a planned timeline of when different applications will be tested, the members involved in those test case executions, and the overall anticipated completion date of those test case executions.
Let’s Try it Ourselves
In this section, we will deploy a sample infrastructure/application (which we will name “VRAPACHEWS”) in AWS in which we will conduct the process of creating and performing the execution of a couple of different resilient test cases. The infrastructure and application we will deploy will consist of the following:
- A VPC and associated subnets
- An AutoScaling Group of EC2 Instances
- These EC2 Instances will be hosting a basic Apache Web Server application (“VRAPACHEWS”)
- An Application Elastic Load Balancer that sits in front of and distributes traffic to the AutoScaling Group of instances.
- This Application Elastic Load Balancer will be associated with three subnets in the VPC.
- AWS CloudWatch Alarms
- One for monitoring and alerting on Autoscaling Group High CPU Utilization
- One for monitoring and alerting on the number of Unhealthy ALB Target Group Hosts
- AWS SNS Topic for sending out alert notifications when failure occurs in the infrastructure.
We will then produce two different resiliency test cases that we can conduct ourselves. Below are the details of the different test cases:
| Test Case – 1 | |
|---|---|
| Application/ID | VRAPACHEWS-TC1 |
| Category | Resource |
| Scenario | High CPU Utilization |
| Description | Simulate a CPU utilization of 100% on an EC2 Instance within an AutoScaling Group |
| AWS Service(s) | AWS EC2, AWS AutoScaling |
| Application Components | “VRAPACHEWS” Apache Web Server web application |
| Tools/Utilities Used | Linux CLI Bash script |
| Expected Outcome | – It is expected the CPU utilization metrics for the AutoScaling Group will remain 100% for a certain amount of time. – A CloudWatch Alarm should be triggered for CPU utilization and an SNS email notification should be sent out with details about the CloudWatch alarm being triggered due to CPU utilization breaking the desired threshold. – The AutoScaling Group should automatically scale-out and increase the number of EC2 Instances in the group by one to help meet the demand for CPU utilization. |
| Execution Steps | 1. Connect to the targeted EC2 Instance via AWS Systems Manager Session Manager. 2. Run the provided script/commands to begin the 100% CPU load. 3. Monitor the CPU utilization metrics of the AutoScaling Group and check to see that the associated CloudWatch Alarm has been triggered. 4. Confirm that you have received an SNS email notification about the detection of CPU utilization breaking the desired threshold. 5. Check to see a new EC2 Instance has been automatically spun up in the AutoScaling Group to help meet the demand for high CPU utilization across the group of EC2 Instances |
| Actual Results | TBD |
| Status | Pending Execution |
Figure-02
| Test Case – 2 | |
|---|---|
| Application/ID | VRAPACHEWS-TC2 |
| Category | Network |
| Scenario | Network Latency |
| Description | Simulate network latency of 6 seconds for incoming traffic on port 80 inside one of the selected EC2 Instances in the AutoScaling Group |
| AWS Service(s) | AWS EC2, AWS AutoScaling, AWS Application Elastic Load Balancer |
| Application Components | “VRAPACHEWS” Apache Web Server web application |
| Tools/Utilities Used | Linux tc (Traffic Control) utility command |
| Expected Outcome | – It is expected that the ALB Target Group health check (which is pinging the EC2 Instance on port 80) will eventually consider the EC2 Instance to be unhealthy due to a ping response time greater than the allowed threshold. – When the EC2 Instance Target is considered unhealthy, it will trigger the CloudWatch alarm set for it and send an SNS notification that the desired Unhealthy Host Count has gone above the threshold. – The Unhealthy target EC2 Instance should be terminated and the AutoScaling Group should provision a new EC2 Instance to take its place. – During the execution of this test case, the VRAPACHEWS application should still be reachable by hitting the ELB DNS on port 80. |
| Execution Steps | 1. Connect to the targeted EC2 Instance via AWS Systems Manager Session Manager. 2. Run the provided script/commands to introduce a network latency of 6 seconds on port 80. 3. Monitor the status of the EC2 Instance’s ALB target health. 4. Confirm that the EC2 Instance target becomes “unhealthy”, and wait to see if the EC2 Instance is automatically terminated from the AutoScaling Group and that a new instance is being provisioned. Also, confirm that you have received an SNS email notification about the detection of Unhealthy Hosts being above the desired threshold. 5. Check to see that a new ALB Target has been registered as healthy with the new EC2 Instance that has been provisioned as part of the AutoScaling Group. 6. Confirm that the VRAPACHEWS web application is still reachable by hitting the ELB DNS on port 80. |
| Actual Results | TBD |
| Status | Pending Execution |
Figure-03
Setup
Here we will create an AWS Cloud9 Environment for you to execute the activities described within this blog post:
- Go to the AWS Cloud9 console and select Create Environment
- Enter a Name and Description
- Select Next Step
- Select Create a new instance for the environment (EC2)
- Select t2.micro
- Leave the Cost-saving setting at the After 30-minute (default) option enabled
- Select Next Step
- Review best practices and select Create Environment
- Once your Cloud environment has been launched, open a new terminal in Cloud9
Clone the Repository
From your Cloud9 terminal, run the following commands:
git clone https://github.com/VerticalRelevance/aws-resiliency-blogcd aws-resiliency-blog./scripts/install_ssm_session_plugin.sh(this will install the AWS SSM Session Manager CLI Plugin onto your Cloud9 environment.
Launch the Testing Environment
We will now launch a testing environment and application (named “VRAPACHEWS”) that will consist of the following resources:
- A VPC with both private and public subnets.
- An Autoscaling Group of EC2 Instances that will host the VRAPACHEWS application.
- An Application Elastic Load Balancer that sits in front of the AutoScaling Group and listens on port 80.
- Two CloudWatch Alarms – one for alerting on high Autoscaling Group CPU utilization and the other for alerting on the number of ELB Target Group unhealthy targets rising above a certain threshold.
- An SNS Topic for sending out email alerts when CloudWatch alarms are triggered.
From your Cloud9 terminal, run the following script (replace “EMAIL_ADDRESS” with your email address for receiving SNS notifications):
./scripts/launch_test_environment.sh EMAIL_ADDRESS
#!/bin/bash STACK_NAME="VRAPACHEWS-RESILIENCY-TEST-ENVIRONMENT" if [ -z $EMAIL_ADDRESS ]; then EMAIL_ADDRESS=$1; fi # Error out if EMAIL_ADDRESS Environment Variable or CLI argument is not provided if [ -z $EMAIL_ADDRESS ]; then echo "ERROR: Please provide your email address for AWS SNS notifications! Example: './scripts/launch_test_environment.sh [email protected]'" && exit 1; fi echo "Launching CloudFormation Stack ${STACK_NAME} for Resiliency Testing Environment" # Deploy VRAPACHEWS resiliency testing environment and web application aws cloudformation deploy \ --capabilities CAPABILITY_NAMED_IAM \ --template-file cfn_templates/vrapachews.yml \ --stack-name $STACK_NAME \ --parameter-overrides SnsTopicEmail=$EMAIL_ADDRESS
Test Case Executions
In this section, we will go through the process of performing the executions for Test Case 1 (VRAPACHEWS-TC1) and Test Case 2 (VRAPACHEWS-TC2). This will involve following the steps for executing the test cases, observing what happens during the simulation of failure/load, and then recording the results.
Test Case 1 Execution
For the VRAPACHEWS-TC1 test case, we will be simulating a CPU utilization of 100% on the Autoscaling Group. Currently, this Autoscaling group should only have one EC2 Instance running. Let’s follow the execution steps:
- From your Cloud9 terminal, run the following script to start an SSM shell session into the EC2 Instance that is part of the AutoScaling Group:
-
./scripts/start_ssm_session.sh
-
#!/bin/bash
VRAPACHEWS_STACK_NAME="VRAPACHEWS-RESILIENCY-TEST-ENVIRONMENT"
# Grab Autoscaling Group name from VRAPACHEWS-RESILIENCY-TEST-ENVIRONMENT CFN Stack Output
ASG_NAME=$(aws cloudformation describe-stacks \
--stack-name $VRAPACHEWS_STACK_NAME \
--query 'Stacks[0].Outputs[?OutputKey==`AutoScalingGroup`].OutputValue' \
--output text)
# Grab one of the EC2 Instance IDs from the Autoscaling Group
INSTANCE_ID=$(aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-names $ASG_NAME \
--query 'AutoScalingGroups[0].Instances[0].InstanceId' \
--output text)
echo "Starting SSM shell session with EC2 Instance ${INSTANCE_ID}"
# Start SSM shell session in EC2 Instance
aws ssm start-session \
--target $INSTANCE_ID
- When inside the EC2 Instance, run the following commands to start the 100% CPU utilization simulation:
Sudo su -for i in 1; do while : ; do : ; done & done
- Monitor the CloudWatch alarm for the CPU utilization metric and confirm that it enters into an “ALARM” state.
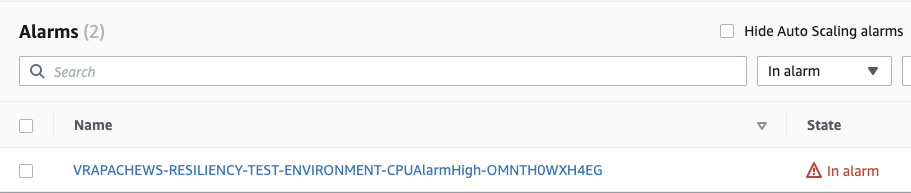
Figure-04
- Confirm that you received an SNS email notification alerting you that the CloudWatch alarm was triggered.

Figure-05
- Confirm that a new EC2 Instance has automatically been provisioned in the Autoscaling Group to reduce the overall CPU utilization.
- While still inside the target EC2 Instance, run the following command to kill the process that is producing 100% CPU utilization:
killall bash - Run the command
exituntil you have exited out of the SSM shell session and are back in the terminal of your Cloud9 environment.
Test Case 2 Execution
For the VRAPACHEWS-TC2 test case, we will be simulating a network latency of 6 seconds, on port 80, on one of the EC2 Instances in the Autoscaling Group. This should cause the ALB’s Target Group Health Check to mark the affected target EC2 Instance as unhealthy which will then cause the Autoscaling group to terminate the instance and spin up a new one.
Before we begin the steps for execution, let’s increase the desired amount of instances in our Autoscaling group from 1 to 2. From your Cloud9 terminal, run the following script: ./scripts/update_asg.sh 2
Now let’s follow the execution steps:
- From your Cloud9 terminal, run the following script to start an SSM shell session into one of the EC2 Instances that is part of the AutoScaling Group:
./scripts/start_ssm_session.sh
- When inside the EC2 Instance, run the following commands to introduce a network latency of 6 seconds on port 80 :
Sudo su -sudo tc qdisc add dev eth0 root handle 1: prio priomap 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0sudo tc qdisc add dev eth0 parent 1:2 handle 20: netem delay 3000mssudo tc filter add dev eth0 parent 1:0 protocol ip u32 match ip sport 80 0xffff flowid 1:2
- Monitor the status of the ALB Target Group targets’ health checks
- Confirm that the target instance has been marked as unhealthy and that it is eventually terminated from the Autoscaling Group. Also check to see that a SNS email alert notification was sent out informing that the number of unhealthy targets, associated with the target group, has risen above the desired threshold. Confirm that a new EC2 Instance is being provisioned

Figure-06

Figure-07
- Confirm that a new healthy target EC2 Instance has been registered with the ELB.
- Confirm that the VRAPACHEWS web application is still reachable by hitting the ELB DNS endpoint.
As we can see from these test case executions, our environment is resilient when encountering a situation that introduces a much higher amount of CPU utilization into the Autoscaling Group and when a network latency of seconds is introduced to affect our application port 80. Our environment was able to scale out automatically to meet the CPU utilization demand and was able to automatically detect and replace the unhealthy EC2 Instance that had a network latency issue. We were also successfully alerted when these events occurred via AWS SNS email notifications. From the information we gathered here, we can now create a record of our test case executions such as below:
Test Case – 1
| Application/ID | VRAPACHEWS-TC1 |
| Actual Results | Upon introducing a simulated CPU utilization load of 100% on the target instance, the following occurred: – The CloudWatch Alarm for CPU utilization was triggered and sent off an SNS email alert notification. – The Autoscaling Group automatically provisioned a second instance in the group to help meet the high demand of CPU utilization. |
| Status | Executed |
Figure-08
Test Case – 2
| Application/ID | VRAPACHEWS-TC2 |
| Actual Results | Upon introducing a simulated network latency of 6 seconds on the targeted EC2 Instance on port 80, the following occurred: – The target EC2 Instance was marked as unhealthy by the target group and was then terminated by the Autoscaling Group – An SNS email notification was sent out to alert us that the CloudWatch Alarm for the Unhealthy Host Count threshold was broken. – A new EC2 Instance was spun up to replace the affected one and was marked as a new healthy registered target. The VRAPACHEWS web application was reachable throughout the execution of the test case. |
| Status | Executed |
Figure-09
Conclusion
In this blog article, we discussed the fundamentals of implementing a resiliency testing strategy framework within AWS. For financial services companies, it is critical to get a jump start on resiliency assessment and testing as soon as possible, no matter what level of maturity they may be within the cloud. This is a lengthy process that encompasses many steps and potential roadblocks along the way so it is essential to establish the foundations of how you plan to assess the resiliency of your architecture, organize the record-keeping material for assessment/documentation, and execute those resiliency test cases as early on as possible to allow for an accurate determination of the resiliency of your architectural presence within AWS.
At a high level of maintaining reliability and resiliency within the cloud, AWS recommends the following as industry-standard best practices:
- Use runbooks for standard activities such as deployment: Runbooks are the predefined steps used to achieve specific outcomes. Use runbooks to perform standard activities, whether done manually or automatically. Examples include deploying a workload, patching it, or making DNS modifications.
- Integrate functional testing as part of your deployment: Functional tests are run as part of automated deployment. If success criteria are not met, the pipeline is halted or rolled back.
- Integrate resiliency testing as part of your deployment: Resiliency tests (as part of chaos engineering) are run as part of the automated deployment pipeline in a pre-prod environment.
- Deploy using immutable infrastructure: This is a model that mandates that no updates, security patches, or configuration changes happen in-place on production workloads. When a change is needed, the architecture is built onto new infrastructure and deployed into production.
- Deploy changes with automation: Deployments and patching are automated to eliminate the negative impact.
We have a framework along with a library of 400+ test cases specifically designed for accelerating our customer’s resiliency assessments and testing plans. If you have critical applications that you’re moving to AWS and need to meet resiliency requirements, contact us today.
All of the source code for this solution is located at: https://github.com/VerticalRelevance/aws-resiliency-blog
Source: https://wa.aws.amazon.com/wat.question.REL_8.en.html
