Prior to recent advancements in data lake philosophies, traditional data warehouse strategies were the design of choice, often requiring frequent operational overhead while creating an additional layer of considerable complexity between data lake producers and consumers. Over time, this often results in a high-cost and/or unreliable working model that consistently produces more cost, and more operational overhead, as the size of your warehouse data increases.
Lake House architectures can reduce or eliminate the need for a data warehouse by leveraging object-storage querying mechanisms, eliminating the need for data transfers between a data lake and a data warehouse. Lake House architectures build on Data Lake concepts to incorporate components that facilitate features such as:
- Data Ingestion & Curation & Automated Orchestration of Processes Involved
- Data Lake Exposure of Data Lake Resources to Multiple Accounts through a Data Governance Account
- Data Mesh (or the ability to allocate GRANT rights) to Consumer Account Data Lake Admins
- Data Lake Querying from Consumer Accounts using Athena and/or Redshift Spectrum, without moving queried data out of the data lake
A Lake House effectively utilizes a set of Catalog resources across AWS accounts. The AWS account is transformed into an account with new permission expectations. This Foundation is the utmost importance of account-structuring when one plans out this ‘technical line-of-business. This requires a strong understanding of account structuring and organizational units. If businesses are embarking on this journey for the first time, it’s critical that explicit time is taken to plan out how this will be set up, orchestrated, monitored, managed, and then even further enabled for development with the organization, moving forward. Do not underestimate the importance of this.
What to Expect
The list below outlines the top-level sections to be explored throughout the remainder of the write-up. The sections are organized in a first-to-last fashion with respect to the general flow of data in a Lake House architecture.
- Ingestion & Curation Engine – The process of sourcing, cleaning, and preparing data into a reputable, consumption-ready state.
- Data Lakes in a Lake House Architecture – The process and components involved in the creation of a shareable Catalog reference of consumable data within a data lake.
- Data Mesh Scalability and Compliance Enablement – How a data lake becomes a scalable, managed, shared, compliant, and cost-effective Lake House.
Blueprint: VerticalRelevance/LakeHouseFoundations-Blueprint (github.com)
Ingestion & Curation Engine
Ingestion & curation is a critical part of building an effective Lake House. It is the process that facilitates getting data into a data lake. This process will vary widely from use-case to use-case. For example, one might curate big data cluster logging into an S3 bucket, partition it by cluster, and ultimately utilize it for cluster monitoring and alerting. In another scenario, one might curate employee access logging across several systems, where the curation process normalizes access logs across several types of systems. The point is that each of these different data sources will all have distinct ingestion and curation processes to get source data into the data lake.
In the context of the Lake House architecture, curation design is critical. Curation design depends on many factors. Data might need to be leveraged in real-time, or data might need to be normalized and stored in different locations depending on the business need for speed, cost-savings, and/or future audit enablement. In any case, the ingestion process of choice should be tailored to fit a given use case.
Components
- Glue Jobs – Move and manipulate data from the Landing Zone account to the Lake House account. Within the Lake House account, there are a series of Jobs that process the data into the curation bucket to be leveraged for Lake House sharing.
- Glue Workflows – Stitch the Glue processing jobs together within any single account.
- Lambda – Trigger the execution of Glue Workflows in each account.
- Step Function – Automate the triggering of data processing across accounts
- Glue Crawlers – Crawl specified data within the Lake House account and populate the Governance account Lake Formation Catalog.
How It Works
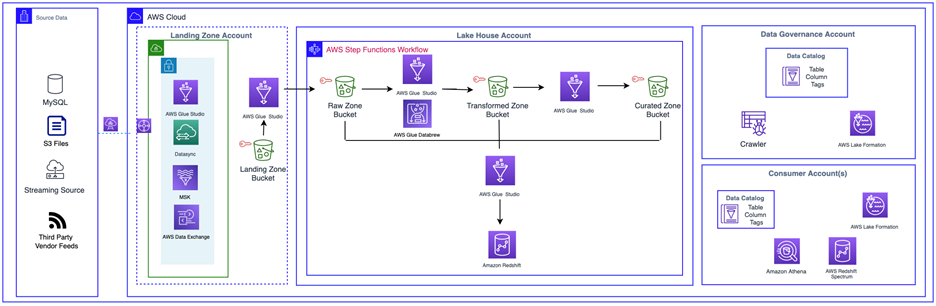
Ingestion & curation for this Lake House architecture is orchestrated by a Step Function. This step function is manually triggered to facilitate live demos. However, the step function could be triggered on a regular schedule (daily, weekly, etc.) to facilitate automated scheduled curation of data. The Step function is located in the Lake House Account, and triggers Lambda functions that kick off a series of 3 Glue Workflows. There is one Glue Workflow located in each of the Landing Zone, Lake House, and Governance accounts. Note that this design is not one that accommodates real (or near-real) time analytics or dashboarding. However, this design is one that could be extended to support such use-cases.
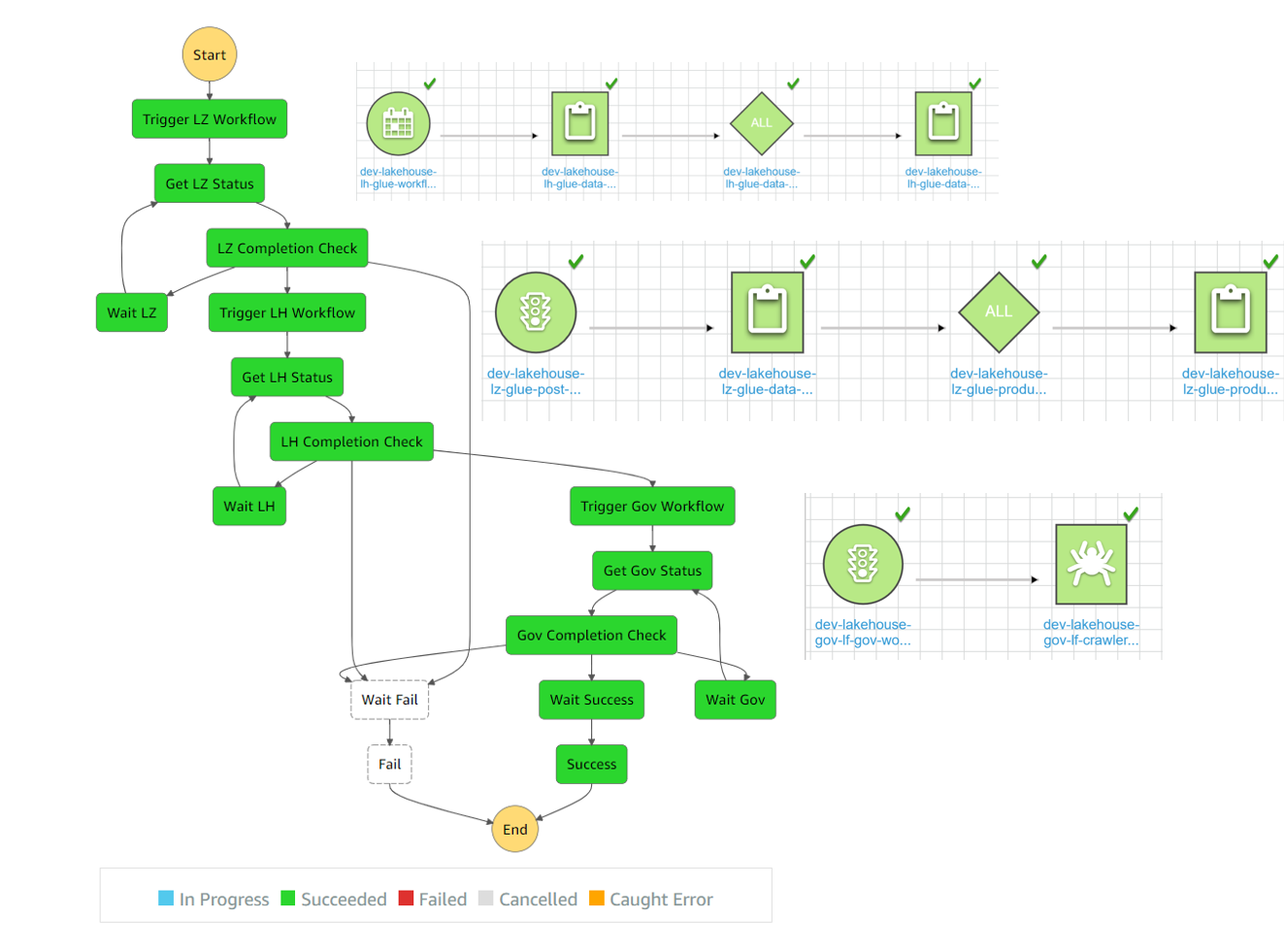
- The first workflow triggers data to be pushed into the Lake House account.
- The second workflow is a Data Lake curation workflow located in the Lake House account.
- The final workflow is in the Governance account that first crawls the curated bucket in the Lake House account, and then further creates a Data Catalog table based off the data it crawled in the curated bucket
Blueprint
- Lake House Account: Step Function Orchestration Template – CloudFormation template to deploy the Step-Function and Glue Workflow initiator Lambda function in the Lake House account.
- Lake House Account: Step Function State Machine Orchestrator Definition – A JSON file that defines that Ingestion/Curation Step-Function. This state machine is deployed in the Lake House account, but works with Lambda functions across the Landing Zone, Lake House, and Governance accounts.
- Lake House Account: Glue and Lambda Definitions – CloudFormation template to deploy Glue resources in the Lake House Account, as well as the Lambda resources for running Glue.
- Lake House Account: Lambda source file for Lake House Account Glue Workflow – Python file used by the Lake House account Lambda function for initiating and checking the status of the Glue Workflow in the Lake House Account.
- Landing Zone Account: Glue & Lambda Definitions – CloudFormation template to deploy Glue resources in the Landing Zone Account, as well as the Lambda resources for running Glue.
- Landing Zone Account: Lambda source file for Glue Workflow – Python file used by the Landing Zone account Lambda function for initiating and checking the status of the Glue Workflow in the Landing Zone account.
- Governance Account: Glue Workflow Glue & Lambda Definitions – CloudFormation template to deploy Glue resources in the Governance Account, as well as the Lambda resources for running Glue. This file also contains the definitions for Governance Account Lake Formation resources.
- Governance Account: Glue Workflow Lambda source file for Governance Account Glue Workflow – Python file used by the Landing Zone account Lambda function for initiating and checking the status of the Glue Workflow in the Landing Zone account.
Lake House Data Lakes
Data Lakes are commonly used to collect, organize, and leverage data for any number of reasons. They consist of large or extremely large sets of data. Organizations have a business need to leverage these data sets for purposes such as:
- Business-driven data decisions
- System logging
- Auditing
- Migrations
- Analytics
The data lake is the core component of a Lake House. In a Lake House architecture, the Data Lake components are abstracted as metadata into Lake Formation Catalog tables. This abstraction allows for query engines such as Athena or Redshift Spectrum to query the Data Lake objects within S3 directly, regardless of the storage format of any specific Data Lake data set. This is an important feature, as data with distinct characteristics can be best utilized when stored in data formats conducive to its anticipated use.
Explicit care should be taken when designing the partitioning strategy for any given data set, as this will be a major cost factor when a consumer of the data lake resource needs to perform filtered queries. Limiting a query to filter only by partitioned fields will prevent scans of an entire target data set within the Data Lake. This can potentially happen anytime an unfiltered query is run against an entire Catalog Table.
Components
- Lake Formation – Enables identification, catalog population, and access-controlled sharing of Data Lake resources.
- Data Sources – Lake Formation supports data from the following resources: S3, RDS, and CloudTrail
- Glue Crawlers – Glue Crawlers are leveraged for Lake Formation to determine the structure of a data lake resources, and populate the Lake Formation Catalog
How It Works
AWS has created Lake Formation services to ease the burden of data lake population, management, and exposure. There are many aspects to how a Lake Formation data lake can work. The idea is that AWS has provided and entire suite of tools to enable businesses to tackle the problems of the most common use-cases found when utilizing a data lake.
Many of the concepts included in this write-up are what we believe to be the most current, cost-effective data-management architectures fully supported within AWS to date. The following illustrates how we foundationally approach a data lake, and furthermore, a Lake House architecture:
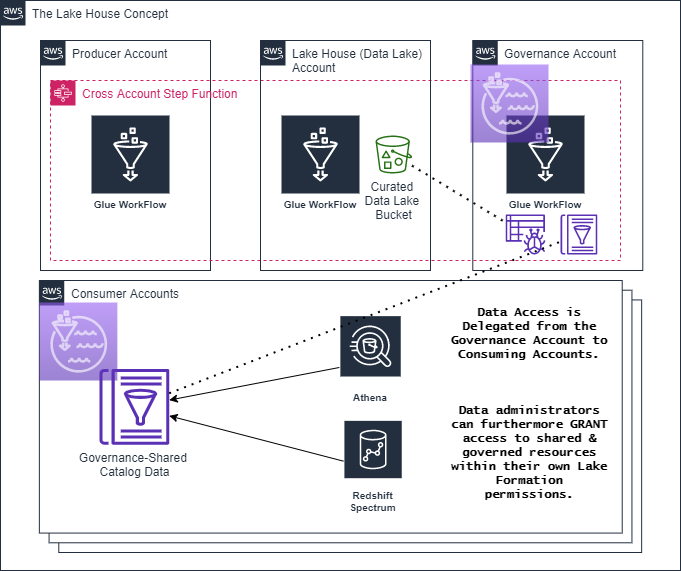
In the above diagram, take notice of the Curated Data Lake Bucket within the Lake House Account. For the purposes of this reference architecture, this bucket holds the data that makes up the Data Lake. However, in practice, it potentially represents a large set of S3 buckets, as well as any number of other data sources ultimately targeted to be exposed through the Governance account Lake Formation Catalog.
The Glue Crawler, shown in the Governance account, crawls the S3 bucket to automatically determine its data schema and create configured associated Database(s) and Table(s) within the Governance Account Catalog. The Governance account then further shares Tables within the catalog to target, appropriate accounts.
Blueprint
- Lake House Account: S3 Buckets – CloudFormation template that defines the ‘curated-zone-bucket’ in the Lake House Account. For this reference architecture, this bucket represents our curated data lake.
- Governance Account: Lake Formation Template – CloudFormation template defining a Lake Formation VPC in the Governance Account, as well as a glue crawler which crawls the Lake House account curated data lake bucket to create the Lake Formation Catalog Database and Table(s).
Data Mesh
The data mesh concept is important to understand when working with Data Lake Governance in Lake House Architecture.
Within an organization’s data, there are compliance regulations that specify how data must be managed. This compliance can often have complex requirements that require complex access delegation. Lake Formation and the use of a Lake House architecture ease the burden of realizing these complex compliance regulations using the Data Mesh concept.
The following illustrates a high-level conceptual diagram of a data mesh architecture:
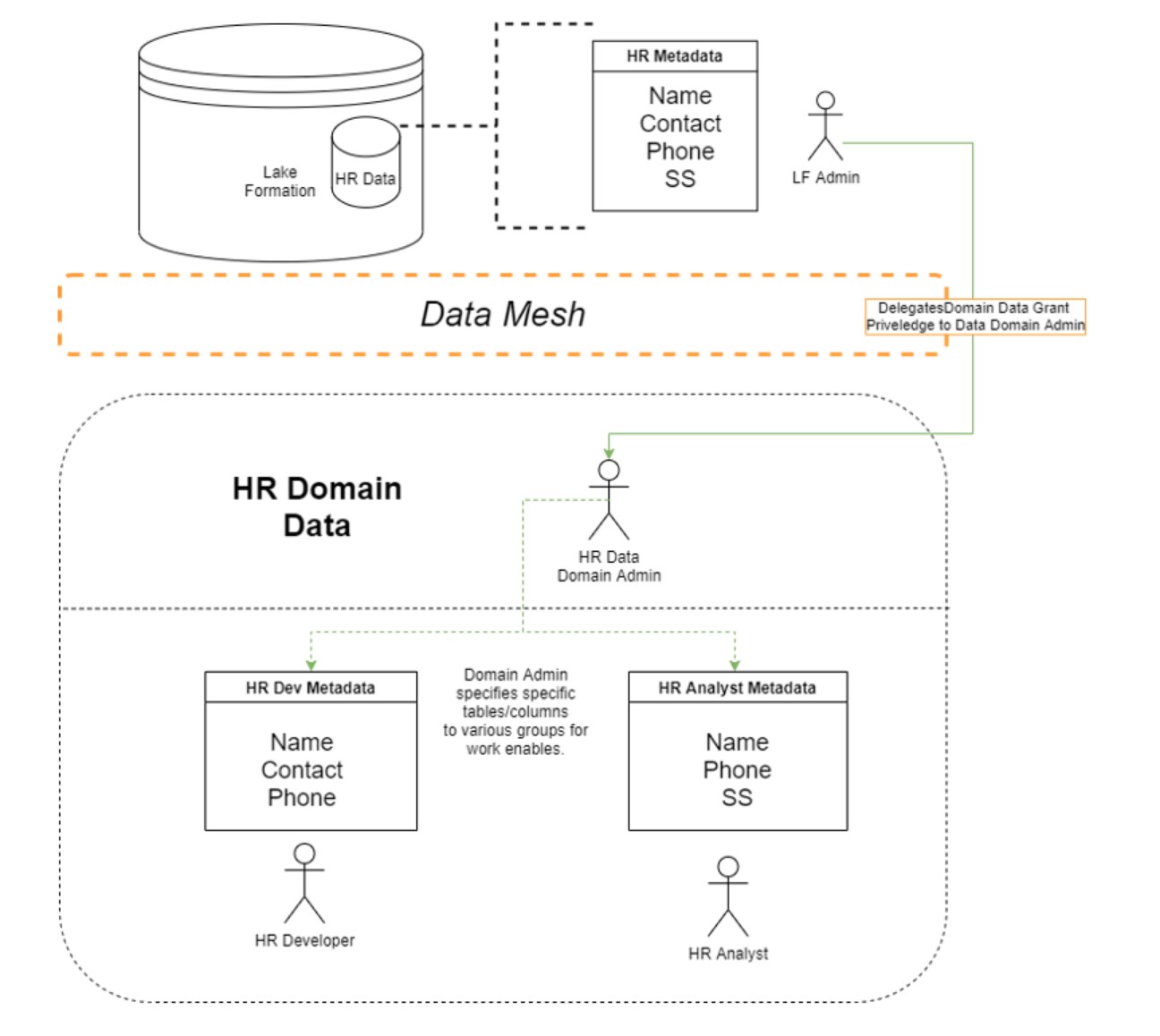
A data mesh is the ability for one account to, not only Grant access to a shared data resource but also the ability for the exposing account to provide GRANT allocation permission to any Consuming account. This allows consuming accounts to control access to data within their own accounts.
Rather than the Governance Account Lake Formation Administrator having to permission access for all users of the data in the consuming account, the Lake House Admin can simply provide the ability for a Lake Formation Administrator in the consuming account to further grant access to other users or roles that require access to that data to do their work.
Components
- Lake Formation – Lake Formation Catalog and Permissions features
- Data Lake Sources – The source(s) of the data that make up the Lake Formation data lake
- Data Lake Consumers – The Consumers of the Lake Formation catalog that leverage data within the data lake
- Data Lake Administrators – People configured for a specific AWS Account to be an Account’s sole Lake Formation data lake administrator
How It Works
The data mesh is achieved through both Lake Formation GRANT permission features, as well as a Hub-and-Spoke Data Governance Lake Formation account design. See the two sections below for more information on each of these distinct aspects, and the third on how they work together to create a true data mesh capability.
GRANT Permission Features
Lake Formation provides features that can contribute to the realization of a Lake House Architecture. Features such as sharing Catalog tables to other accounts, limiting what columns are shared and what can be done with those sources are foundational, but there is 1 very important feature that enables the data mesh concept. That feature is the ability for a data owner to assign GRANT rights to another IAM entity within an account, or another AWS Lake Formation account entirely.
Hub-and-Spoke Data Governance Account Design
An important thing to understand when designing a Lake House is how an organization’s accounts are structured. Creating a separate and distinct Data Governance account is, in our opinion, best practice. It facilitates a ‘hub-and-spoke’ data mesh design pattern. This pattern is realized when the Governance account delegates relevant GRANT privileges to the Lake Formation Administrator or Data Domain Administrator(s) in another account. Furthermore, the same type of hub-and-spoke model for referencing data from several data lakes in separate accounts, and abstracting them all within a single (Governance account) Lake Formation Catalog provides a similar benefit. This type of account design provides the most flexible, secure, and supportable data mesh design.
This design enables the centralized governance of one or more data lakes of any size, with many distinct data sets, to be selectively delegated out to any number of other accounts. The governance account data-delegator no longer needs to be concerned with how those data resource allocations will be further restricted within any single account. Rather, the data governance team can simply be focused on the task of ensuring the right data sources are delegated to the appropriate accounts.
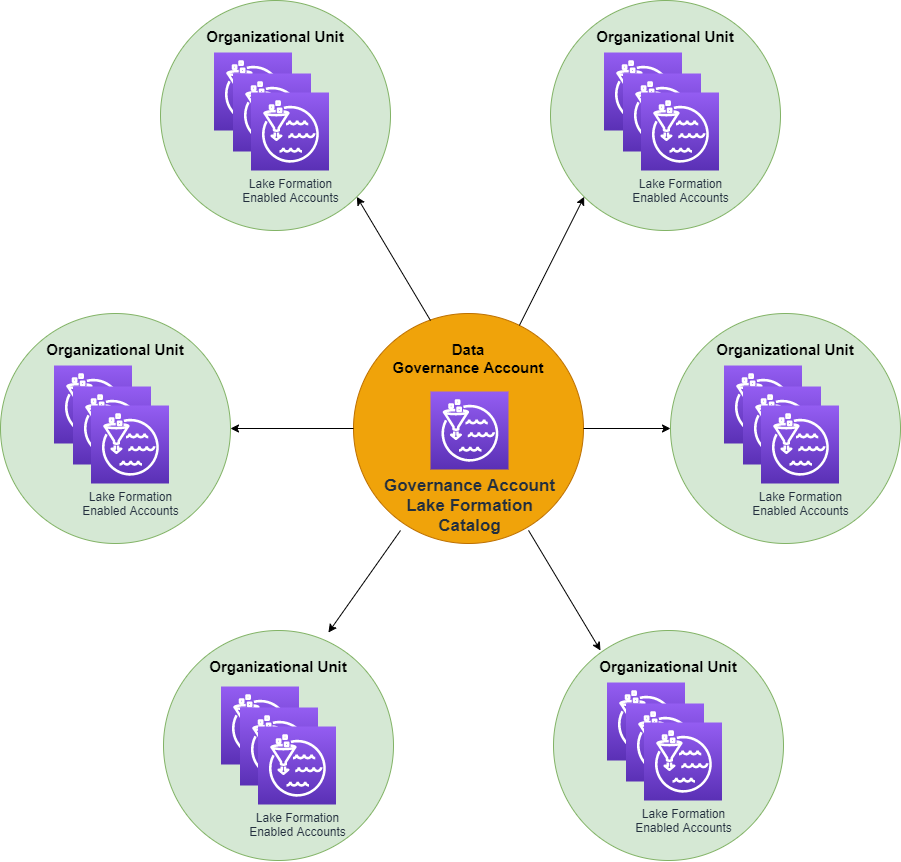
The data mesh concept is fundamentally important to the operational scalability of a centrally managed data lake architecture. A big reason for this is due to data compliance regulations often found in Financial Services organizations. Access management, access monitoring, as well as audit tracing should and must be part of any scalable, centralized, and compliant data management system. The data mesh design enables a single Data Governance team to be responsible for the access management of all the data within an organization, in all its organizational domains, and in all those domains accounts. From there the account Lake Formation administrator or the account data administrator can uphold the responsibility of delegating access to resources, components, roles, or users within that specific account.
Achieving Compliance
There are 2 main areas of interest regarding data compliance regulations:
- Who has access to shared data?
- What data is shared?
The concept of a Lake House inherently encompasses the concept of a data mesh. With that in mind, a data lake administrator has the capability to share data to any Account, User, Group, or Role in Lake Formation permissions.
This enables column-level data lake resource access granularity to be provisioned for specific entities in need of data consumption. When this provisioning is performed, it is performed for a certain Lake Formation Catalog resource. This provides a great deal of flexibility to meet the requirements of the two main areas of interest.
Blueprint
- Governance Account: Lake Formation Template – CloudFormation template defining a Lake Formation VPC in the Governance Account, as well as a glue crawler which crawls the Lake House account curated data lake bucket to create the Lake Formation Catalog Database and Table(s).
- Consumer Account: Lake Formation Template – Cloudformation template defining the Lake Formation resources needed for this reference architecture. Note that many Lake Formation setup steps are currently not supported in Cloudformation, and must be performed as manual steps. See the README Documentation for more information.
Benefits
- No need to move data into and out of a data warehouse to perform analytics on a Data Lake
- Reduction in operational overhead regarding Data Lake resource access permissions and delegation.
- Centralized data access audit logging and compliance
- Automation of data ingestion and exposure process
- Cost-savings realizations through data
End Result
By implementing a Lake House, an organization can avoid creating a traditional data warehouse. Organizations are enabled to perform cross-account data queries directly against a Lake Formation Data Lake through Redshift Spectrum External Tables and/or Athena. Table and Column-Level access granularity achieved through Lake Formation Permissions. Data Lake Governance enabled through Lake Formation Resource Shares. Multi-regional, parameterized, infrastructure-as-code deployments. Full data flow and processing pipeline with Glue Jobs, orchestrated by a single Step Function.
Interested in learning more?
If you are looking to provide automation, consistency, predictability, and visibility to your software release process contact us today.
