About the Customer
The customer is a payment technology company that more specifically handles credit card authorizations and batch processing for large credit card companies. They have a large percentage of the market and are looking to increase the share while also reducing the risk of a service outage. They are also looking to reduce their dependency on legacy hardware and reduce the MIPS in their data center. In order to accomplish these business outcomes, they have decided to migrate several of their workloads to AWS, of which Vertical Relevance is involved in Authorizations and Batch workstreams.
Key Challenge/Problem Statement
Credit card authorization transactions have both high volumes and stringent SLAs that incur a financial cost to the customer if they are not adhered to. The current peak transaction rate is 5,000 transactions a second and needs to be able to scale to 10,000 transactions based on the company’s projections. They also have an SLA with their clients that transactions need to occur within 250 milliseconds, or the customer will incur a financial penalty. Due to these requirements, they have an RTO and RPO of zero and require that any solution delivered by AWS for the Authorizations product must be resilient from any kind of failure and deliver the above requirements.
State of Customer’s Business Prior to Engagement
The client currently utilizes a mainframe built 50 years ago to handle their credit card services running in a primary data center in Georgia. They are in the process of migrating their functionality from the mainframe to a more modern microservice architecture within the cloud. The authorization application was already rewritten by the customer to run on Kubernetes, and batch processing is being rewritten with an AWS partner to a microservices architecture. Vertical Relevance was brought in to help design the cloud architecture and perform validation to confirm that it will meet the customers resiliency standards.
Proposed Solution & Architecture
Holistic FMEA Strategy
Vertical Relevance began by creating the foundation for the customer to use Failure Mode and Effect Analysis (FMEA Testing) by conducting the following activities.
- Gathering the customer’s Non-Functional Requirements (NFRs). These included but were not limited to Recovery Time Objective (RTO), Recovery Point Objective (RPO), and Latency.
- Identifying relevant test categories, failure events, and app components
- Creating a test scenario taxonomy
- Creating the test cases for the scenarios to ensure test coverage of their applications
This testing approach was reviewed with the customer to ensure that the correct stakeholders would be engaged and the strategy for planning and executing test cases would lead to the proper results. Test cases also went through an extensive review process where they were reviewed multiple times internally before being presented to the client for approval. This allowed us to ensure that the expected results were captured to identify a passing test case. The following diagram outlines the end-to-end process that we designed.
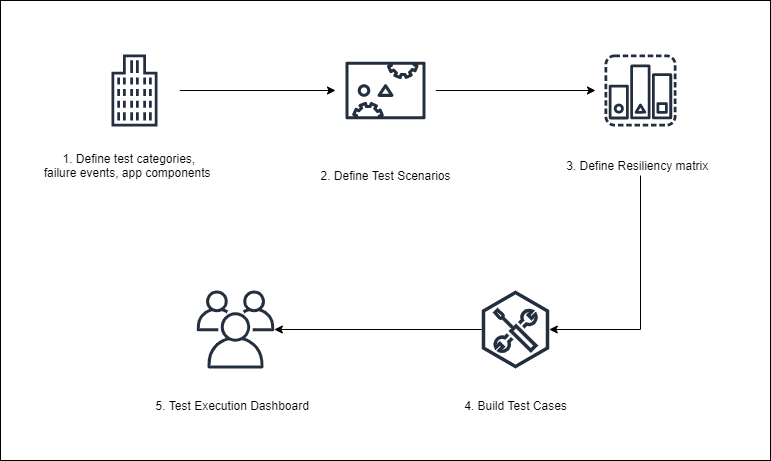
Once the environment was created, we were able to execute the test cases and deliver the results to the appropriate teams to either certify the resiliency of the product or make recommendations on improvements to be made to the application.
Automated Resiliency Testing Solution
Once this holistic FMEA strategy was put into place, we created a Resiliency Automation Framework to automatically run perform test cases we have previously defined. By automating the resiliency testing process, the customer was able to save time by eliminating manual testing, performing tests more frequently, and getting consistent results each round of testing. The following diagram outlines the architecture of the automated resiliency solution we created.
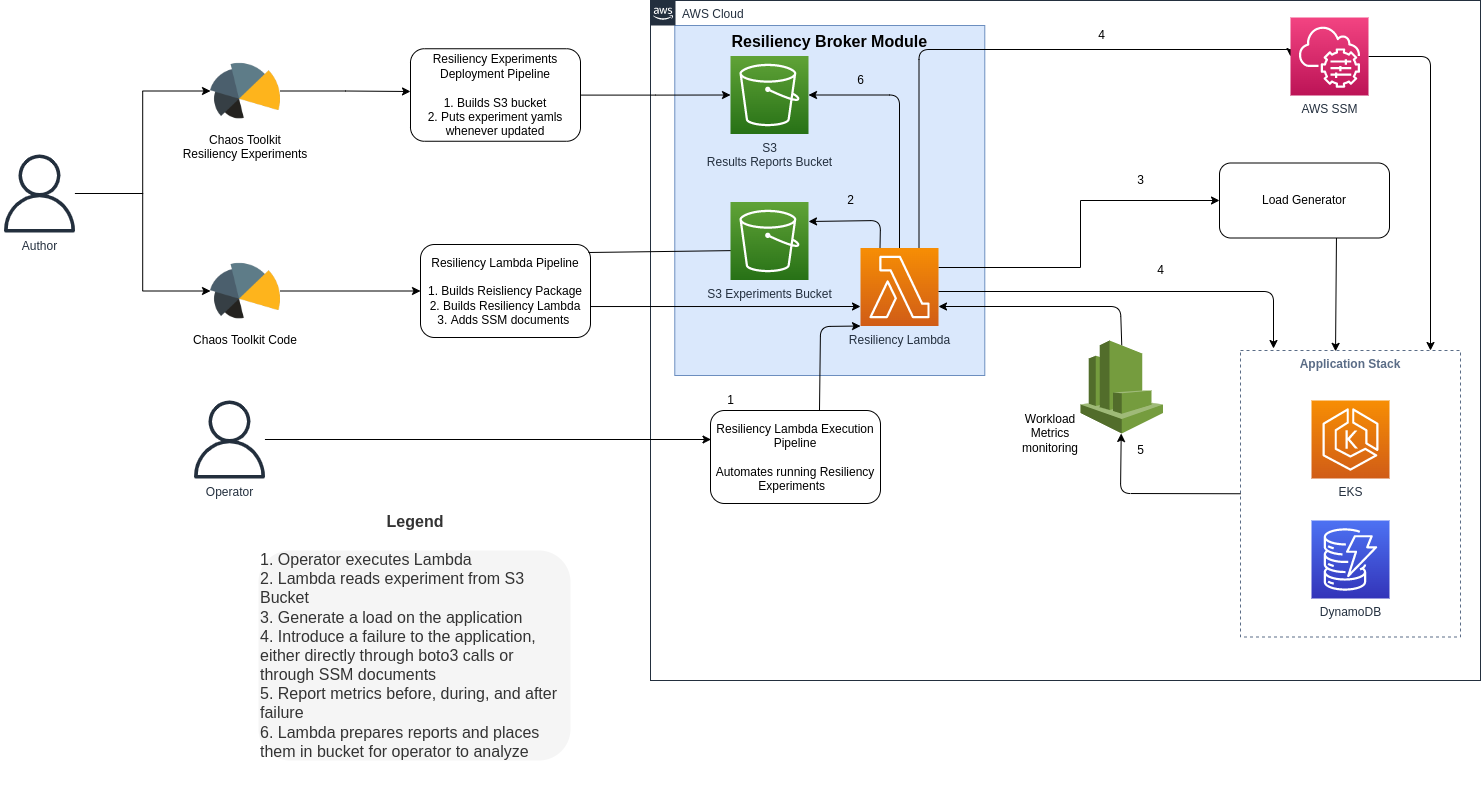
The automated resiliency testing solution utilized an open-source Python tool called Chaos Toolkit. Chaos Toolkit allows Site Reliability Engineering (SRE) teams to write Python code to introduce failure into the cloud environment and validate the infrastructure’s response. To define, updated, and maintain the library of experiments we created a CI/CD pipeline that was connected to the SRE team’s resiliency experiment code repository. Each time that a change was committed to the repository, the pipeline performed code linting and updated the experiments in the environment.
The core functionality of this solution was deployed to Lambda such that you simply had to provide your experiment parameters and invoke the Lambda to perform resiliency tests. After each Lambda execution finishes and the experiment is completed, the results are stored in an S3 bucket to be accessed directly or passed to downstream systems for analysis.
AWS Services Tested
AWS Compute Services – Lambda, EC2, EKS, ALB
AWS Storage Services – S3, EFS, ELB
AWS Database – DynamoDB, RDS(Postgres DB)
AWS Networking Services – VPC, Subnets
AWS Management and Governance Services – CloudWatch, Config, CloudTrail, SSM
AWS Security, Identity, Compliance Services – IAM, Key Management Service
Third-party applications or solutions tested
- Apache Spark
- Apache Airflow
- SQ Data
- Kafka
- Prometheus
- Self-Managed Kubernetes
- Chaos Toolkit
- ELK
Outcome Metrics
- Created over 400 Test Cases to determine the resiliency of the architecture and application
- Utilized a FMEA framework to allow the customer to define and execute Resiliency Testing to certify their architecture per their requirements
- Improved architecture quality as we challenge the architecture team to create resilient applications
Summary
The project delivered two key products – the FMEA Test Framework with Failure Scenarios and Test Cases, and the Resiliency Automation Framework that executes the test cases. Going through these activities is not only creating a road for Resiliency testing to be completed, but it has also improved the architecture of applications being taken to the cloud as we have worked with and challenged the people who are making key decisions. This has allowed our team to influence the design of the workloads and create a path that will validate that the customer will be able to operate with full knowledge of how their system works in the event of a failure.
