Conduct frequent and comprehensive performance testing while gaining insight into how changes to your system affect performance
Overview
Financial institutions expect high-volume low latency systems. These expectations are expressed as non-functional requirements (NFRs) and are present to ensure the performance of the system at the level of service specified in the Service Level Agreements (SLAs) with their customers. Performance tests attempt to demonstrate whether the system is meeting performance-related NFRs.
Performance testing is challenging. Not all organizations do it effectively. It is not possible to gain meaningful insight into your system’s latency by simply using a web browser or a tool such as Postman to send single requests. It is impossible to gain insight into the throughput by having a bunch of devs or users “play” with the system manually and see how it behaves. These methods will not produce quality benchmarks. Some organizations use tools dedicated to performance testing. This is a step in the right direction; however, simply using the tools does not guarantee insightful benchmarks will be produced. In other words, no conclusions can be drawn from these measurements taken in the above scenarios.
Conducting performance tests properly results in an output called a benchmark. These benchmarks can then be used to determine if the system is meeting the NFRs. In Systems Performance 1 Brenden Gregg describes the qualities of a good benchmark. These qualities exist because performance testing is not a one-and-done activity. It is used to evaluate whether a system is achieving NFRs and whether it is reasonable to conclude that it will in the future. This final clause has two implications: it means that the results need to be observable and easily presented. It also means that they should be easy to produce again, reproducible and runnable, as the system changes to meet new demands from the business and its customer base.
This solution will guide the reader through the process of performance testing in such a manner that results in the creation of insightful artifacts. These artifacts are insightful in that conclusions regarding the performance of the system can be drawn and ultimately be determined whether the NFRs are being met. In more mature systems, guidance can be provided as to what components should be looked at for remediation. These artifacts produce insight into the system and are the result of sound experimental design, rigor in executing the tests (mini-experiments), and thoughtful analysis of the results.
This solution targets an audience serving a variety of organizations. Each of these organizations has their own needs. Because of this, do not consider this solution as a checklist of things to be marked off or as a step-by-step guide that leads to success. Instead, consider this a guide for building a toolbox. Apply thought and carefully consider where your organization is at in the journey and guide it through building the tools that improve our insight into our system.
Prescriptive Guidance
Before diving into the Performance Testing Solution, it is important to acknowledge the philosophies and concepts related to effective performance testing. Performances tests attempt to capture and report on the system as a snapshot in time.
Consider the system under test. Modern systems have components distributed in a networked (cloud) solution that will undergo software changes and hardware reconfigurations. Similarly, the performance testing system will undergo changes. Given the complicated and changing nature of these systems, sound experimental design and reporting are required for effective performance testing and reporting. Doing these things right ultimately results in systems and characterizations of those systems that demonstrably realize (or not) the business desires captured in the SLAs.
In this section, we will discuss types of performance tests, performance workflow best practices, benchmarking best practices, and general performance testing best practices.
Definitions
- The business: the organization that is providing the service or product that is the application. This is the entity that is guiding the development of and has a stake in the profitability of the service or product.
- Non-functional requirement (NFR): this is any requirement not related to a feature of the application. Performance requirements fall into this category. Common performance related NFRs are latency and throughput.
- Service Level Agreement: these are metrics provided by a vendor to the customer that describe how the customer can expect the application to perform during reasonable use. Expect each metric in the SLA to have an accompanying NFR.
- System Under Test: the thing that a tester or test-system tests. This is the application, or a component if it, (product or service) that performance tests are testing.
- Latency: broadly, the time between a stimulus and the response. Here it describes the time between sending a request, such as an http request, and receiving the response. Typically expressed as the maximum unit of time some percentage of the samples experience as latency. For example, a “P99 of 250 milliseconds (ms)” means that 99% of the requests had a latency of 250ms or less.
- Throughput: broadly, the amount of data flowing through a system per unit time. Often expressed as Requests per Second “RPS” equivalent to Transactions per Second (TPS). Could also appear has bytes or bits per second as is common with internet service providers for example.
- Benchmark: a capture of some metric or metrics of the system under test. This is the output of performance testing and should include the metrics listed in NFRs and SLAs.
- Performance tests as code: the practice of using code to implement performance tests. Contrast this to tools that have a UI without the ability to change the underlying code.
- Accuracy: An experimental or observed value is accurate when it is arbitrarily close to the actual value. For example, a latency measurement at P99 of 280ms when the actual accepted latency is 285ms at P99 is more accurate than a latency measurement at P99 of 250ms. Do not confuse accuracy with precision.
- Precision: An experimental or observed value is precise when it achieves some minimum level of certainty. For example, a latency measurement reporting a value at P99 of 287ms is more precise than a measurement reporting a value at P99 of 290ms (rounded to the nearest millisecond versus tens of milliseconds.) Not necessarily more accurate.
- Users: A way of describing the amount of load being generated by the load generator of a performance test system. This is the number of virtual users the system is simulating at a given time. As the number of users increases, so will the load increase on the system under test.
- Spawn Rate: the rate at which the number of virtual or simulated users are added or removed per unit time in a performance test. Conceptually, this is also the rate at which the amount of load changes per unit time. For example, a capacity test might start with 100 users and ramp up to 400 users at 20 users/second. This is the spawn rate.
- Dwell: this is the amount of time a system will remain in a given state without making changes to a control value. For example, a capacity test might start with 100 users and ramp up to 400 users at 20 users/second. Then, once it gets to 400 users, it might dwell here for some amount of time to see if 400 users causes any.
Types of Performance Tests
Different test types address different needs of the organization and the testing process itself. This is not a checklist nor a step-by-step guidance. These are the tools to have in your toolbox as you build the performance testing system and begin to generate reports and guide your client through the process of achieving and demonstrating the levels of service they have committed to.
Smoke Tests
These help ensure that results from further simulations are going to be valid by testing the functionality of the system, should be run before additional load tests are run, and act as a gate in front of them. If the system under test is not functioning properly, results from further performance testing will be invalid because the system is not fully operational. If, for example, the application code is early-exiting, then parts of the system will remain unexercised. In this way, smoke tests act as gates for further testing to help prevent time wasted time and cost.
Component Tests
These characterize the performance of discrete components of the system by exercising them in isolation. In this way, additional insight is gained on a part of the system. By running different scenarios against a specific component additional information can be determined about how it is performing or failing to perform. For example, a component test might only test one microservice out of many that would make up an entire application.
Capacity Tests
These determine the number of users that the system will support based on latency and throughput levels. Advisable to start “low” then ramp and dwell. If tests are passing, double the number of users, i.e. ramp, dwell, verify tests pass. Once tests start failing, apply binary search through a series of ramp up/down, dwell, and checks to determine safe user levels. Be prepared to exercise judgment in the trade-off in measurement error (granularity) and accuracy.
Stress Tests
Use stress tests to determine which components of the system fail first. The load profile for these tests is a ramp and dwell doubling the number of users each time. Additional tooling or monitoring may be required to gain insight into which part of the system is failing. This information is useful in understanding where additional engineering effort can be applied to get the system performing at the level desired. Or, if stress tests reveal failure above acceptable levels, it is useful in understanding where the system is likely to break first if user levels increase.
Endurance Tests
Use endurance Tests to test the stability of your application for long periods of time. This will help identify problems such as memory and leaks and corruption. To perform these tests, ramp the number of users to a supported “high load” and let the tests run for a “long time” such as several hours.
Spike Tests
Use spike tests to understand the system’s ability to recover from brief spikes in traffic. Ramp to “normal” load. Dwell. Ramp to some high load above normal, then dwell. Spike tests, return to normal load levels relatively quickly as opposed to endurance tests. Verify that the system recovers from these spikes in traffic. Perhaps in an existing application, there are known user spikes for some periods of the day. Running realistic performance tests will allow the organization insight into whether the NFRs are being met in realistic scenarios.
Conducting a Performance Workflow
Conduct an Architecture and SLA Review
An important first step in performance testing is the business and technical teams working together to review the architecture and the SLAs. The results of this review will be used to derive NFRs for the system and sub-systems. From these NFRs, test plans will be created. If there is data on how users are currently interacting with the system, include this in the review. These interactions might be called workflows or user journeys.
Defining NFRs such as latency and throughput should drive the architecture of your workload and help you follow performance best practices. NFRs and existing user workflows or journeys is important information that will improve the quality of the performance tests by creating realistic test cases. Realistic test cases help to demonstrate that meeting the NFRs in tests correlates to meeting the SLAs when human users are interacting with the production system. These NFRs are critical components of your business requirements, so clearly stating them in conjunction with creating realistic test cases will ensure your system will meet or exceed your business needs not only in test, but also in production which is where it matters to the business.
Consider using these questions to assist you in teasing out latent requirements and information:
- Customer expectations/SLAs: What is the maximum time a user should have to wait for a response from the system? What is the maximum amount of traffic you expect your system to support? How long? Are there traffic spikes during certain times of the day? Year? Are there multiple applications in scope for the project? Do any of these questions change depending on the application?
- SLA to NFR translations: How do the customer-facing SLAs (end-to-end) map to architecture and component boundaries? What NFRs must each component meet to meet the needs of the SLA as expressed on the system end-to-end?
- Existing traffic: What are your current traffic patterns? How do these patterns vary? How do these traffic conditions affect the architecture and its components? How do these patterns map to types of performance tests?
- Current performance: What parts of your system are known or suspected to be non-performant? How critical are these systems? Are they currently being remediated? If no, why not?
- Trade-offs and cost: Performance requirements add cost and complexity. Are your desired NFRs in line with your schedule and budget? How much time and budget have been allotted for remediation? Do this remediation time and budget allow time for addressing both known and unknown performance deficiencies?
Create Performance Test Plans
Performance tests are intended to validate whether the system has been built within specifications presented by the business to its customers in the form of SLAs. Because these SLAs and the architecture that implements it has been reviewed (see above) tests are created that clearly indicate whether the system passes or fails.
These tests, ideally, should include both component-level and end-to-end tests. End-to-end or system tests are useful in that they provide insight into the whole system and whether it is meeting the SLAs. This is especially true when being given real test data. When these tests fail, having insight into what is causing these failures is most useful in performing remediation. This is where observability tools and component tests are handy. Remediation activities are expensive as they require human analysis data interpretation. Quality benchmarks from realistic performance tests help provide this insight.
Because these tests are captures of a changing system in time the need arises to treat these performance snapshots as benchmarks. The business is trusting that these tests, created by automating users and creating a test environment “like-prod”, are a valid representation of what the actual users will experience.
Performance Test Workflows
- Deploy the infrastructure to be tested (if necessary)
- Capture the configuration of the target and test systems
- Generate load
- Gather data for reports
- Store the reports and configurations
- Tear down unneeded infrastructure
Write and Automate Performance Tests
So that insightful test artifacts (i.e. benchmarks) are produced, build the following things:
Capture Configuration: In this step, record the configurations of the system under test and the test system itself. Record the things that could affect the performance of either system. Answer the question, “If I have to repeat this, what information would I need?” Automate as much of this as you can. Create templates for what cannot be automated, so as to minimize human error around data collection. Make use of knowledge-sharing resources such as internal wikis, so that there is no gate-keeping between data generators and data consumers.
Load Generator: In this step, build the thing that will attack and target various parts of the system usually by providing a stimulus, e.g. HTTP request. It should be able to provide varying levels of load. We recommend performance tests as code, that is using some type of automated load generation framework that allows for custom automation built from code. Improving automation improves the consistency of results, and the insights from results, and allows humans to focus on analyzing and remediating.
Reports Generator: Many of the load generation frameworks have report generation built-in. To some extent you “get this for free.” On the other hand, we recommend validating the results of the load generation framework with observability tools. This way there is independent verification of the accuracy (not to be confused with precision) of the reports from the load generator. These results should be captured alongside the configuration as described above.
Runner: This component runs the tests and orchestrates capturing the configuration and reports data. Having a runner external to the load generator helps guard against vendor-lockin and enforce the best practices described in the document.
Storage: This component stores the configurations and their corresponding tests. This way changes in configuration can be compared against test results. This allows the organization to map configurations to services levels. Consider the case where the traffic on the system under test might change seasonally or with new (phased) rollout. In this way, agreements can be met while attaining cost-savings from right-sizing the infrastructure.
Execute Tests
Ideally, the performance test runner does the following at the press of a button. If not, make sure there are repeatable human methods that minimize errors. Capture the configurations of target and tester. Generate the load, execute the tests, and finally store test results and configurations. Here is another place automation gains can really pay off. If the load and report generation has been automated, then the humans can spend their time observing the results and analyzing in real-time while the tests are underway. They can be diving into issues and consider follow-on tests free from the task of orchestrating the performance testing task itself.
Remediation
If tests fail be sure to analyze the results before assuming the test was failing. This healthy dose of skepticism applies to passing tests too, especially early in the development of the performance tests. Use observability tools and reports to be sure that the plateau or drop-off in performance was in fact due to a problem with the system being tested and not the test system itself. If it is an end-to-end test that is failing, consider running component tests for more insight. Consider running different types of tests to gain more insight. An end-to-end capacity test might be failing and require a stress test of a component due to (potentially) depending on traffic patterns in the full system.
Consider the usual suspects: network, storage, memory, and CPU. Understand that many of these can be changed quickly through modern development practices. So, a system that was failing today might have been fine even this morning, but there is a configuration change that caused the non-performance. This is why we discuss two different use cases for performance tests: pipeline and stand-alone longer-running systems.
Benchmarking Best Practices
All these types of performance tests produce benchmarks of the application. We recommend the following and are modeled after the ideas in Section 12.1.2 of [1]. As you read through these, imagine them happening in the context of validating the performance of software and infrastructure systems during development and maintenance. Because these systems are expected to have ongoing development and maintenance, these systems are expected to change. This makes it difficult to benchmark. Benchmarks capture the performance of the system as a snapshot in time. As the system changes, benchmarks become less insightful.
Performance tests and their results should be:
- Repeatable. Running the tests again with the same system under test and test system configurations should yield the same results. Automate as much as you can.
- Observable. Observability tools should, ideally, be in place to ensure that the results generated by the performance testing tool are accurate.
- Portable. Configuring the test system to test other targets should be consistent in-process and reporting and require as little human meddling as possible in switch over.
- Easily presented. NFRs and SLAs are written in easily understood, if slightly technical, language. Test results should be presented in this same language.
- Realistic. Performance tests that create conditions similar to how the user pool will interact with the system, demonstrate the intent of the SLAs and that is to make the application usable.
- Runnable. Performance tests, like functional tests, should be easy to run. This way, people actually run them. Automate as much as you can. This will help reduce the effort to run and make them less prone to (human) error.
General Performance Test Best Practices
The above Benchmarking Best Practices lead to the following more prescriptive guidelines when building the Performance Testing System:
We recommend implementing performance tests as code.
Avoid relying on manual UI tools such as Postman or a web browser for performance testing outside of smoke testing to ensure the system under test is functional. Some UI-based tools specifically designed for performance testing can still be difficult to work with and still follow the best practices listed here. For these reasons, consider it is well worth the initial time investment to create performance testing codes well suited to your needs and the needs of the organization.
Code craft rules apply: DRY, SOLID, etc. As the test code becomes more complex, look for ways to test your code with automated tests. It may not make sense to unit or integration test the entire performance testing code base. But, where you can test the code that you write outside of the framework you are using.
As applications become more complex, so does the way that users can interact with them. Functional tests exercise the system under test and verify that it performs the correct actions. Performance testing requires some level of simulation around how users are going to use different parts of the system and understanding how those interactions in different and common parts of the system affect the performance of the application as a whole.
Similar to automated user tests, this introduces the notion of scenarios or work-flows. Some of the users might be logging in to check the balance, others will be logging in to transfer money, and others might log in to analyze their spending. This is where having well-crafted code becomes quite valuable in writing maintainable and valid tests quickly.
We recommend making it easy for humans to perform what cannot be automated.
When parts of the report or configuration captor cannot be automated, then use templates so that it is clear what additional information should be added.
We recommend having observability tools outside the performance test system.
Build observability tools external to the performance testing system. These tools should report the values of the NFRs and SLAs alongside the performance testing system. This will help build confidence in the metrics being reported.
Also, build tools that observe the resources and health of both the system under test and the performance testing system. Having these things will help tune both the application under test and the performance testing system.
We recommend analyzing the results.
As with functional tests, test continuously throughout the development and product lifecycle. Ensure there is enough time to understand test results and perform remediation ahead of product development milestones. Performance tests should be realistic. These are snapshots of the system in time. The closer these metrics are taken from a system mimicking real usage of the system, the more accurate these results will be.
Take time to understand the results of performance tests whether they pass or fail. Ensure the tests are valid and are testing what you think they are testing. Some frameworks report latency and throughput without making it obvious that the requests were failing, i.e. returning HTTP status codes 400 or greater. These data should be discarded for this reason, favor frameworks that generate clear and accurate reports.
You have spent days if not weeks or months understanding and tuning the performance needs of the system. Do your work justice by providing meaningful reports and visualizations to the client. While performance tests are tests in that they pass or fail, there is also much more data associated with load tests because they are characterizing the performance of the system as a snapshot in time. This is valuable information.
Many of the tools provide rich data visualizations. Spend some time understanding them. Spend time understanding what specifications and metrics are important to your client and why. Tools are shiny things. Don’t allow yourself to get distracted. Focus on the best practices. Pay close attention to the areas of the reports that provide metrics on the NFRs of the product. Understand the difference between accuracy and precision. Check results against observability tools. Also, check the metrics that report on the resources and health of the system. This is all valuable information in tuning the system.
We recommend using a tool that uses an open workload model.
Some of the performance tests require generating loads above what the system under test can handle. We are intentionally causing errors on the system under test, or at least we intend to. In order to do this, we are going to need to create test systems that follow an open workload model. This is in contrast to some test tools, that use a closed workload model. In the closed workload model, the load generator will never generate more load than the system under test can handle.2 If you are doing performance testing in a closed workload system. Take care to understand the differences.
We recommend having tests in a CI/CD pipeline.
Consider two load testing needs. First, we want to be able to well understand and characterize the performance of our system, so that we understand if we are meeting the SLAs. Second, we don’t want code changes to the app to break the performance. We want one to be relatively short running tests. The second can be much longer running tests.
The first case (stand-alone characterization) requires a suite of performance characterization tests that are intended to run for a longer time such as endurance tests or spike tests. If infrastructure is needed for these tests, have a pipeline devoted to it. Having load tests with realistic scenarios will provide better insight into the performance of the system in production and under actual load. Creating realistic environments not only applies to systems under test, but also test environments. Make sure that your load test system can scale to levels that are needed for the tests. Finally, these tests should be running in their own environment as close to production as possible to ensure that these tests would apply to the production system.
The second case (pipeline) is a suite of performance tests that run in the pipeline of the system under test. These tests will ensure the performance baseline of the application. Early on these tests may not necessarily be set to the performance specifications of the final application. These tests should be relatively fast running as typically expected from a CI/CD pipeline. These tests will identify breaking performance changes introduced during development similar to functionality and functional tests.
Having these jobs in place will allow for better benchmarking. Make sure the results of the performance tests are accessible to those that would find them valuable. The tests will be repeatable and repeated with each run of the pipeline. Changes to the system that breaks performance tests can be identified with each change and remediated. One of the challenges of not having load tests in the pipeline is ensuring that enough time is present before a big event to not only test the system, but also perform remediation.
We recommend having a distributed load generating system.
Financial institutions with applications running in the cloud are expecting reliable high throughput systems. Expect in order to achieve the throughput needed for testing such systems a distributed performance testing system will be required.
In this setup, there will be a master and several workers. The workers should scale to meet the throughput needs of testing the target. The master should interact with the user, control the tests, interface with the rest of the performance test system, and compile the results. Several popular performance testing frameworks have distributed capabilities out of the box, through plug-ins, or extended by other providers.
We recommend a crawl, walk, run approach.
Recall that smoke tests verify the functionality of the system under test. This ensures that the performance tests running after it are valid. Performance tests in their simplest form might only include smoke tests and some simple load tests. These might be sufficient to suit the needs of an application early in its development. Perhaps there aren’t any users yet. Knowing what traffic levels the system supports is an important first step.
Later, additional tests can be added depending on the situation at hand. Consider capacity and spike tests to gain insight into increased traffic levels before major releases. Consider endurance tests to ensure the reliability of the system for long durations.
Finally, as the system matures and it is known how users are interacting with the system. Build out scenarios around the different workflows that users follow. In this way, these load tests become simulations of real usage and allow the organization to continue to improve system reliability.
Some organizations are going to have teams or entire departments dedicated to performance testing. Other organizations, may be reluctant to adopt them. Meet our clients where they are at. Seek to understand why they have the practices that they have and work within those practices to gain their trust and deliver value. As trust is established, then begin to consult and guide them through improving the reliability of their systems.
How can I manage the complexity of my performance test system as it matures?
Take time to understand the framework upon which you are building your performance testing system. Make use of built-in features when you can. This will help reduce the complexity of the code we write.
See earlier sections on performance tests as code and componentization. This is how we can manage complexity in the code that we write and at the same time crawl, then walk, then run. We want to move fast and deliver value quickly. One way to do this would be to start by writing modular component tests. Then, as the org wants to gain further insight into the system, these modular pieces can be reused in testing other components or work together to perform scenario or workflow-based testing on multiple components.
It is certainly acceptable to unbox our selected performance testing framework and begin writing tests, running them, and reporting without much componentization. This is natural. Yet, keep in it mind how you are going to componentize, separate concerns, and scale this system.
As it grows, iterate on the design. While you don’t need to test the framework, if there are no (unit) tests around the behaviors you are adding, be sure to add them. Test drive additional behaviors for bonus points. This will help manage your complexity. As the design improves and concerns separated, begin to create seams where you can share and reuse code.
In mature systems that closely mimic how users are using the application under test, build out scenarios and run those scenarios. If the component modules are properly separated, there should be plenty of opportunity for reuse. Suppose that a workflow will touch several microservices. Proper separation should allow the code implementing a scenario that touches multiple microservices to be built from the code that tests each microservice individually. These microservice test modules would themselves be built from lower-level test modules.
Performance Testing Automation Framework
There are plenty of tools upon which to build a suite of automated performance tests, but for this demonstration we chose Locust. The philosophy of “it’s just Python code” is consistent with our own recommended practices. It provides many of our recommendations out-of-the-box as well.
Using Locust, we define “locustfiles” that define classes that follow the delegation pattern to generate loads against the targets defined in those classes – these targets can be any component of your infrastructure. The amount of load to produce can exist in the locustfile or can be externalized to the web UI or CLI command. The blueprint contains several locustfiles and component libraries that implement different load tests and use cases.
As discussed previously, a performance testing solution is more than just the load generator. A performance test will produce artifacts called benchmarks which are snapshots of the system performance in time. Care must be taken, as explained previously, to ensure these are valid. Having these artifacts to refer and compare as the system grows will aid engineers in maintaining and scaling the system under test to meet the needs of the users. More on this later.
Components
Our framework consists of the following things:
- Infrastructure as code – We use CloudFormation Stacks to standup and teardown our performance testing infrastructure.
- Performance tests as code – As mentioned above, we use Python code and Locust as the tooling for our performance tests. The performance tests are classes defined in Python that inherit from Locust classes. These Locust classes provide the mechanisms to define the target and additional customizations that our tests require.
- Container registry – The builds are containerized and use images stored in public repos or AWS ECR.
- Helm repository – Package the deployments in Helm charts. They are checked-in to source control and packaged to AWS ECR for deployment.
- Load Generator Stack – The performance testing stack running on AWS EKS.
- Reports Repository – Store the reports for others to view using S3.
- Author – The person that is writing the performance tests and maintaining the performance testing system.
- Operator – The person that is using the performance testing system and analyzing the results.
How it works
The Vertical Relevance Automated Performance Testing Framework lowers the barrier to entry in performance tests by providing a starting point upon which a mature solution can be built to meet the needs of your organization.
Like any development process, we begin by analyzing your needs, followed by an architecture review of our solution. From there, performance tests are written to test components of the system under test. As the system matures, the component tests are built into scenario or workflow tests in order to better approximate the load that the system would see in production with multiple components interacting and being tested in real-time.
Implementing this solution begins with writing simple short-running tests against specific components of the system under test. This is done to gain early insight into critical parts of the system under test. Also, by checking the results of these early tests against observability tools external to the performance testing framework, we gain confidence in the results from both the system under test and the performance testing system.
As the system matures, you can expect to add additional tests in several ways. Expect the component tests to evolve into workflow tests where several components of the system are being tested together. Also, the initial short-running tests should be replaced with more sophisticated tests such as capacity tests that determine the number of users (amount of concurrency) the system will support and remain within the specifications of the SLAs.
As the system matures still, expect to add additional tests such as endurance that leverage long-running tests to ensure that the steady-state of the system is performance over long periods of time: hours, days, and weeks. Spike tests could be added to understand how the system recovers from user spikes. Or even stress tests that tax the system to see which components fail first.
Throughout the above process, you can add tests in the pipeline of the application just as you would with function tests. This way you have confidence that performance baselines are being met with each code integration or delivery. Expect a trade-off here between run-time and test comprehensiveness. Pipeline tests that take “too long” to run tend to get turned off. So, strike a balance between test value and run-time. Look to stand-alone characterization tests to provide the bulk of the detailed testing.
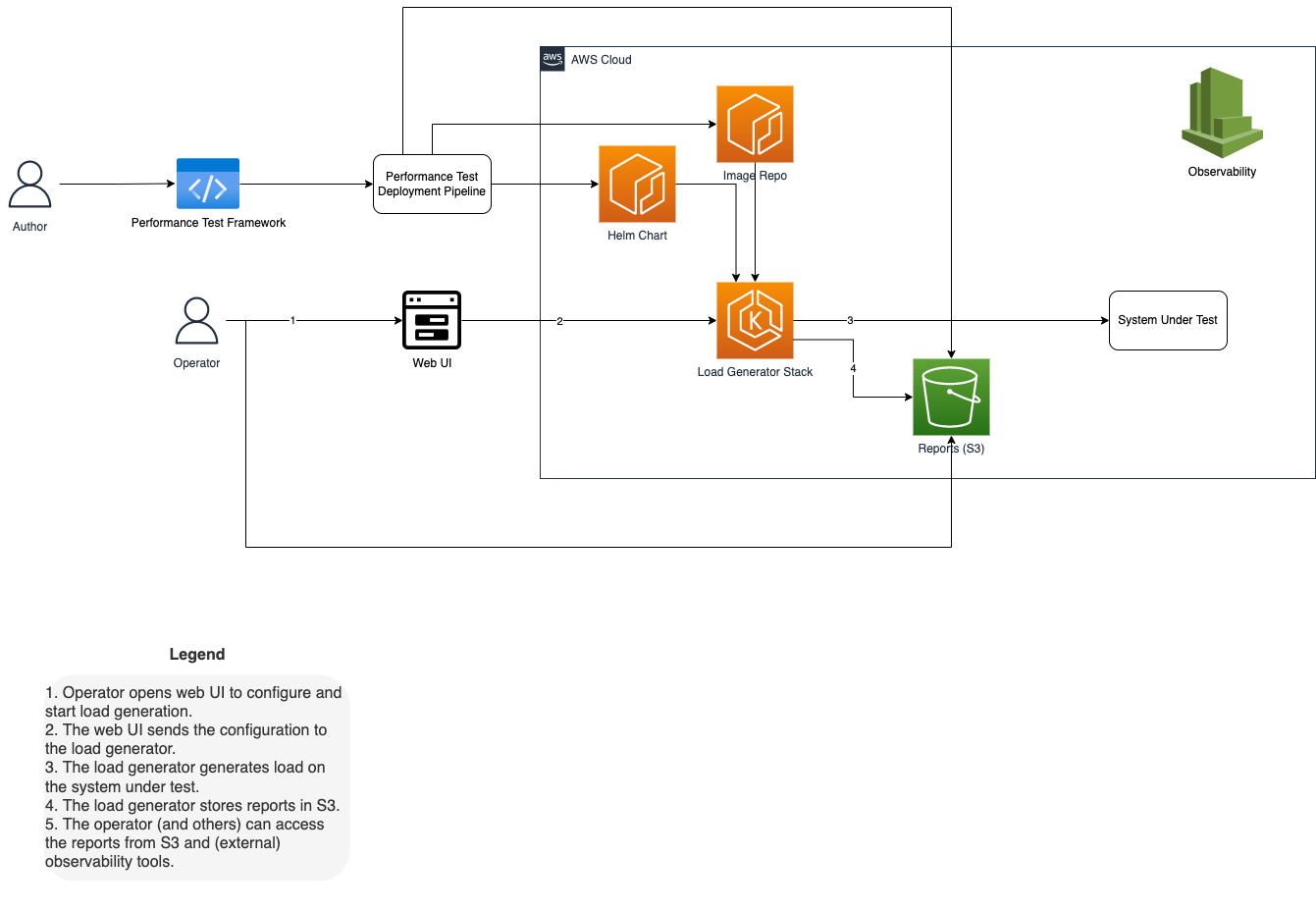
Figure-01
Blueprint
The Performance Testing repository contains the code for standing up automated performance tests with several examples of types of performance tests and use cases. Please see the link for the most up-to-date information on repository contents.
The EKS Cluster application that is being tested in the example above can be found in the EKS Cluster repository.
Benefits
- Performance testing builds confidence that your production systems are going to satisfy service level commitments and user expectations.
- Thorough performance testing helps you uncover and remediate pain points in your system before going to production.
- Collecting and preserving valid benchmarks gives confidence that tests in one environment are repeatable in other environments. Or, that tests with a previous configuration will produce the same or similar results if ran with that same configuration.
- Performance tests exercise your observability tools giving your organization confidence in these tools and processes.
End Result
By following this guidance, you can gain confidence that your production systems are going to meet the current and future demands of your organization and customers. Frequent and comprehensive performance testing is your guard against failing to meet non-functional requirements just as functional tests guard against functional failures. Further, by collecting and preserving the results of these performance tests, you gain insight into how changes to your system affect performance now, in past, and potentially in the future.
