Overview
Once a leadership team has approved migrating their application to AWS, it is critical it is executed quickly and efficiently. The transition time impacts resources normally work on improving existing and delivering new digital products to market, so time is of the essence. Enabling teams to learn about your standards and approaches for architecting and migrating solutions onto AWS is labor intensive and slow. Significant investment in time and cost is needed to train and support the teams’ migrating apps to AWS. The Vertical Relevance Architecture Review Tool (ART) accelerates your team’s development of architectures and migration approaches, lowering cost and time to implementation.
Access to experts within the company (or to AWS consultants if available) is slow and bottle-necked based on their availability supporting multiple application teams. The more experienced team members and consultants are expensive, and it would usually be best to have them focused on strategic projects aligned to business objectives. ART accelerates your team’s development of architecture and migration approaches, removing a significant burden on those expensive team members.
Problem Statement
At the start of your AWS migration program, you need to define your standard architectures for your portfolio of applications on AWS. The architecture needs to meet your corporate technology, security and regulatory standards. Their use will allow your teams to adopt consistent patterns and enable a scalable migration to AWS. Your teams need to be supported in learning these patterns, giving them help to understand these standards and enabling them to develop their application specific architectures and migration plans. Once they are developed, they will typically be reviewed through an Architecture Review Board (ARB) process, to ensure oversight and governance of technology leadership in their design before being brought into production.
It is usually your senior architects who develop your AWS architecture library. Often leadership teams will bring in consultants to aid them. Once your AWS architecture library is ratified with technology leadership, the same senior architects and consultants will work with your application teams to educate them on the standards, answer questions, and support the development of application architectures with iterations of feedback and guidance. The speed of your many application teams going through this cycle is limited by the capacity of those senior architects and consultants working across teams migrating at the same time.
At the end of this manual process, it is very common for applications teams to meet with the ARB to review their architectures. Regularly teams are sent away with feedback that needs to be addressed. They then need to adjust their architecture and then re-schedule with the ARB to gain approval before moving forward with implementation.
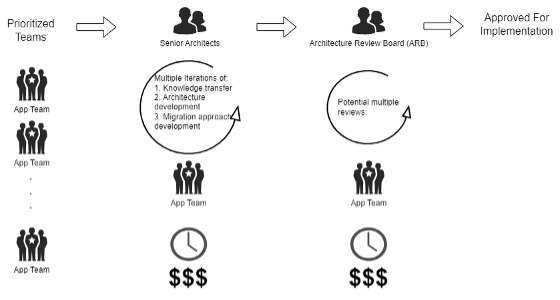
Figure-01
ART delivers a generative AI conversational chatbot providing your teams with guidance from your architecture library and evaluates architectures against your architecture library (and other provided information sources) with recommendations for improvements.
Below is a matrix that outlines the primary problems that are addressed by ART:
| Problem | Details |
| Guidance is only available through a bottlenecked architects and ARB | The design of your application architectures and migration approaches can only go as fast as the application teams reading your architecture library documentation and standards, and then scheduling time with your senior architects and consultants who can guide and support the development of a target architecture and proposed migration approach. |
| Developing architectures and migration approaches is time consuming and costly | The time spent by architects, consultants and the technology leadership working with application teams in these cycles is significant and so is the cost. Coordinating schedules for multiple rounds of meeting with application teams, and multi-tasking across multiple application teams takes significant time. The cost of using senior architects and consultants through these processes is expensive. |
| Strategic project opportunity cost | There is an opportunity cost as the senior team members are unable to focus on strategic projects, while supporting the migration program. This slows down business critical projects on improving existing digital products and delivering new digital products or supporting other workstreams like acquisition integrations from M&A activities. |
| Competing architecture guidance published within companies | Sometimes there are architecture standards and guidelines documented at different levels in the organization, and some may be defined differently in different lines of business. It’s challenging for employees to know which standards and guidelines they should follow as they are published openly, without limiting who has access to what. |
The ART module lets you quickly hook in information sources with role-based access control to ensure your application teams see the right architectural standards and guidance.
Solution
Background
Financial Services Organizations need to be competitive and efficient in delivering the best digital experience to their customers. With limited resources for many competing needs, it is important that efficiencies are implemented to enable teams to be independent, with access to the latest information. With the advent in Generative Artificial Intelligence (GenAI) natural language solutions can provide employees with intuitive conversational interactions, presented them with information and links to reference materials in response to their questions whenever they need it. This coupled with Retrieval Augmentation Generation (RAG) techniques, enables the information provided to come from only the information sources your organization wants to use (whether your own intellectual property, or public information sources), and to keep the curated information and the dissemination of it secure within your own network, and not sharing the information or responses back into the public domain.
ART is a RAG GenAI conversational chatbot that enables employees to find answers to their questions against the organization’s information sources such as the architecture library (or libraries), training materials, security and regulatory standards, and operating standards and guidance. The information is kept private to the organization and related information is stored securely within their span of control. The chat history from conversations is saved and can be returned to at any time and continued from where it was left. Role Based Access Control (RBAC) is utilized to ensure employees only interact with information sources they are approved to have access to.
This post will explain the technical details of the ART module, the approach to deploy it, the mechanisms for ingesting content from multiple information sources, how it implements authentication, authorization and RBAC, and the design used to provide users a seamless and secure solution with recorded history of use.
Components
There are two deployment options for ART, depending on which vector database engine you choose to use – either PGVector on AWS Aurora, or AWS OpenSearch. The information below will identify the components implemented depending on which vector database deployment option you choose. The default is to use PGVector on Aurora.
The Vertical Relevance Experiment Module provides:
- Terraform – As an automation-forward practice, this solution uses Terraform for Infrastructure as Code and Make to create and tear down ART’s infrastructure.
- AWS Lambda – Five lambdas are used here:
- Query lambda – For the OpenSearch vector database deployment it creates the embeddings for the user provided request and executes a conversational retrieval chain against the vector database and stores the results in the chat history DynamoDB table. For the Aurora deployment this lambda calls the Aurora Lambda that performs the same by interacting with the Aurora vector database that is deployed in a private subnet.
- History Lambda – to retrieve the list of prior chats submitted by the user.
- Context Lambda – to retrieve the full history of a single conversation for the user, so it can be displayed and continued. The full history includes all the requests made by the user, the answers from the chatbot and all the links to relevant reference materials.
- Add User To Group Lambda – triggered on the user registration confirmation workflow in Cognito to add two Cognito groups to the user: “VR-Architecture-Library” and “VR-Website”. These match the names of the information sources and are part of the solution demonstrating the RBAC approach.
- PGVector on Aurora specific components:
- Create Vector Database Lambda – reads the document chunks and metadata from the SQS queue to populate into the Aurora database.
- Aurora Lambda – creates the embeddings for the request provided and executes a conversational retrieval chain against the vector database and stores the results in the chat history DynamoDB table. This lambda is called from the Query Lambda in the Aurora deployment because this lambda is deployed in the private subnet to be able to connect to the Aurora vector database.
- Lambda Function URLs – Dedicated HTTPS endpoints for the Query, History and Context Lambda functions called directly from the single–page web application conversational chatbot.
- DynamoDB – Stores the context for each conversation for all users in the chat history table.
- AWS Secrets Manager – Stores the secrets for Aurora and OpenSearch vector database authentication.
- AWS S3 – Hosts the web application static contents for the single page web application for the conversational chatbot, and the HTML generated version of the Vertical Relevance Architecture Library we ingest in this example.
- CloudFront – The Content Delivery Network (CDN) that caches the S3 hosted website static content and provides a fast response to browsers.
- AWS Cognito – Implements authentication and uses Cognito groups to implement the authorization approach for RBAC access to individual information sources. The Cognito Hosted UI provides the sign up and sign in UI for ART.
- AWS SQS – Implements the queue for the Create Document Database python module when submitting the document chunks and metadata to be processed by the Create Vector Database Lambda, when using the Aurora vector database option.
- AWS Bedrock – Generates embeddings for vector database using Anthropic Claude V1 Large Language Model (LLM) and Amazon Titan Foundation Model for Generative AI in this example. Other LLMs and Foundation Models can be used based on the organization’s requirements. The choice of LLMs and Foundation Models is outside the scope of this post.
- RDS Proxy – Provides connection pooling, scalability, performance and maintains application availability during database disruptions for the lambdas connecting to the Aurora vector database.
- VPC – VPC network components are implemented for the Aurora vector database deployment option to ensure secure network management for private database resources, by deploying them in private subnets. The components installed are:
- NAT Gateway – to reach the supporting AWS services for the Vector and Aurora Lambdas.
- Private subnets – to deploy the Aurora instance, RDS Proxy and Vector and Aurora Lambdas into.
- Create Document Database Python Module – Python module that creates vector database embeddings for two information sources:
- Vertical Relevance Architecture Library, and
- Solution Spotlights and Module Spotlights published on the Vertical Relevance website under https://www.verticalrelevance.com/category/solution-spotlight/ and https://www.verticalrelevance.com/category/module-spotlights/
Implementation Details
Overview of ART
ART consists of the two information sources that are loaded into the vector database, the python module that uploads the information sources into the vector database, the vector database that is the information store used for the solution and the single page web application that implements the GenAI conversational chatbot. You can extend the module to include other information sources, per your business needs.
ART demonstrates the use of two different information sources:
- Vertical Relevance Architecture Library – which should be cloned from Vertical Relevance Github repository before deploying ART, and
- Solution Spotlights and Module Spotlights published on the Vertical Relevance website under https://www.verticalrelevance.com/category/solution-spotlight/ and https://www.verticalrelevance.com/category/module-spotlights/ , whose URLs and titles are linked in the web_source.txt file
The core Architecture Review Tool (ART) repository houses the ART code and deployment mechanisms, provides a brief overview of the solution and deployment instructions.
Once the infrastructure deployment is run, the Create Document Database module is run to populate the target vector database with the content from the two provided information sources. The Architecture Library information source is also processed during this step into a set of static web pages that are hosted and linked to ART. This demonstrates an integrated web solution and allows the reference links in the provided answers in the conversations to link directly to document references container within the integrated website. The verticalrelevance.com web pages are linked to in the reference documents provided in answers in the conversations to demonstrate how to link to other sources in your intranet or the internet or partner websites. This module is extensible, and many more information sources could be integrated following these patterns to meet your business needs. While this module demonstrates its application in the domain of application modernization onto AWS, it can be used as a GenAI conversational chatbot for any business domain.
Below is a high-level overview of the architecture of the solution.
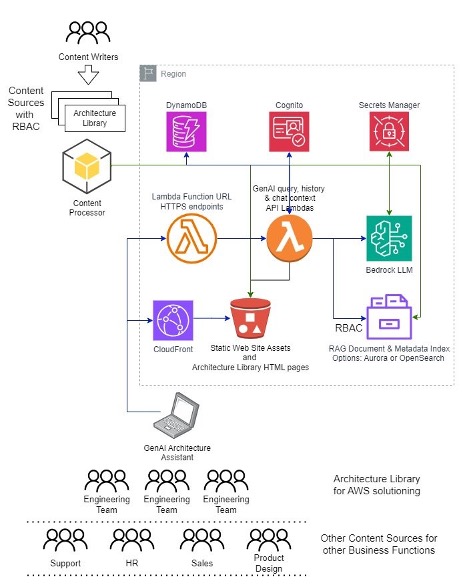
Figure-02
Deployment considerations
Before deploying ART, you need to decide whether you want to deploy the vector database using Aurora with PGVector or OpenSearch. When deploying the solution, specify the choice of vector store using the VECTOR_STORE variable in the Makefile.
Make is used to run the infrastructure deployment using Terraform and AWS CLI commands using variable values from the output of the Terraform deployment.
The deployment of the Aurora with PGVector architecture is below.

Figure-03
Aurora must be deployed to a private subnet, so we deploy a dedicated VPC, public subnet with NAT Gateway for dependent AWS service communication, and private subnets for the Aurora instance and the Vector and Aurora Lambda functions that access the vector database in Aurora.
The deployment of the OpenSearch architecture is below.
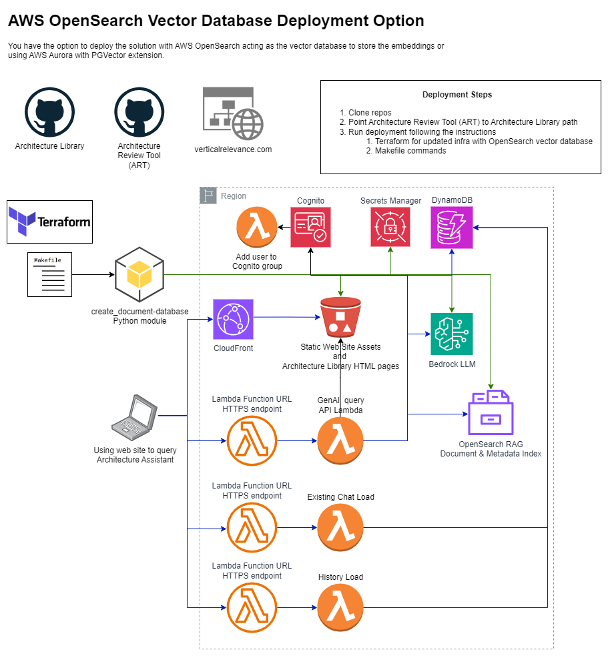
Figure-04
As OpenSearch is accessible securely over direct APIs and the Lambda functions are deployed within the Amazon Virtual Private Cloud (VPC) that is owned by the Lambda service, it is not necessary to deploy your own network infrastructure, if you don’t want to. If you would like to, you would implement an architecture like the Aurora vector database solution above.
Generation of the vector database
Once the solution is deployed, the vector database must be populated with the content from the information sources. Each data source is processed in turn.
The first information source processed is the Vertical Relevance Architecture Library. Before processing the content, the markdown code from the files in the locally cloned folder is translated into HTML. It is then uploaded to the s3 bucket for ART, so it can be accessed and linked to and part of an integrated web solution. After that the content processing flow below is followed:
- For each architecture document loaded, the document using the Langchain DirectoryLoader module and the RecursiveCharacterTextSplitter module to split the documents into overlapping chunks.
- If the vector database deployed is OpenSearch:
- The OpenSearch Index is created (or re-created if it already exists, to clear out prior information) configured for cosine similarity search.
- AWS Bedrock API is called for each document chunk to create the embeddings for the chunk, and the metadata about the chuck is created and inserted into a JSON object the same format as the OpenSearch index.
- The content of the document chunk.
- The embedding is generated from Bedrock.
- The source HTML file web accessible URL for document in the s3 bucket.
- The title of the architecture in the Architecture Library.
- The start index of the chunk within the architecture in the Architecture Library.
- The name of the information store – in this case “VR-Architecture-Library”.
- All JSON embedding and metadata objects for the chunked architectures from the Architecture Library are bulk uploaded to the OpenSearch vector database.
- If the vector database deployed is Aurora:
- The metadata about the chunk is created and inserted into a JSON object.
- The content of the document chunk.
- The source HTML file web accessible URL for document in the s3 bucket.
- The title of the architecture in the Architecture Library.
- The start index of the chunk within the architecture in the Architecture Library.
- The name of the information store – in this case “VR-Architecture-Library”.
- SQS messages are bulk created in the SQS queue for each JSON metadata object for the chunked architectures from the Architecture Library.
- The Create Vector Database Lambda function is called to bulk process the SQS messages.
- It verifies if the PGVector extension has been enabled and if not, it is enabled on the Aurora instance.
- It also creates the Langchain PGVector module database connection to use the AWS Bedrock configuration, so that when objects are inserted, embeddings are automatically created.
- Finally, the bulk JSON objects the SQS messages received are inserted into the vector database during which the Langchain PGVector module automatically generates the embedding for the document chunk.
- The metadata about the chunk is created and inserted into a JSON object.
Once the first information source is processed, the second, the list of web site pages and titles are processed. These are read from the web_sources.txt file in the repository. The content processing flow below is followed.
- For each web page read the document using the Langchain Community WebBaseLoader module and the RecursiveCharacterTextSplitter module to split the documents into overlapping chunks
- If the vector database deployed is OpenSearch:
- The OpenSearch Index is confirmed to exist.
- AWS Bedrock API is called for each web page chunk to create the embeddings for the chunk, and the metadata about the chuck is created and inserted into a JSON object the same format as the OpenSearch index.
- The content of the web page chunk.
- The embedding generated from Bedrock.
- The source URL for the web page.
- The title of the VR solution or module documented on the web page.
- The start index of the chunk within the web page.
- The name of the information store – in this case “VR-Website”.
- All JSON embedding and metadata objects for the chunked web pages are bulk uploaded to the OpenSearch vector database.
- If the vector database deployed is Aurora:
- The metadata about the chunk is created and inserted into a JSON object.
- The content of the web page chunk.
- The source URL for the web page.
- The title of the VR solution or module documented on the web page.
- The start index of the chunk within the web page.
- The name of the information store – in this case “VR-Website”.
- SQS messages are bulk created in the SQS queue for each JSON metadata object for the chunked architectures from the Architecture Library.
- The Create Vector Database Lambda function is called to bulk process the SQS messages.
- It verifies if the PGVector extension has been enabled and if not, it is enabled on the Aurora instance.
- It also creates the Langchain PGVector module database connection to use the AWS Bedrock configuration, so that when objects are inserted, embeddings are automatically created.
- Finally, the bulk JSON objects the SQS messages received are inserted into the vector database during which the Langchain PGVector module automatically generates the embedding for the web page chunk.
- The metadata about the chunk is created and inserted into a JSON object.
Single Page Application
ART is a single page web application. It provides the ability to submit requests that are run against your information sources (in this case the Vertical Relevance Architecture Library and the Vertical Relevance published solution and module papers) and provide natural language responses, including guidance and links to the references it used from your information sources. Users must register with an email and password to access the application.
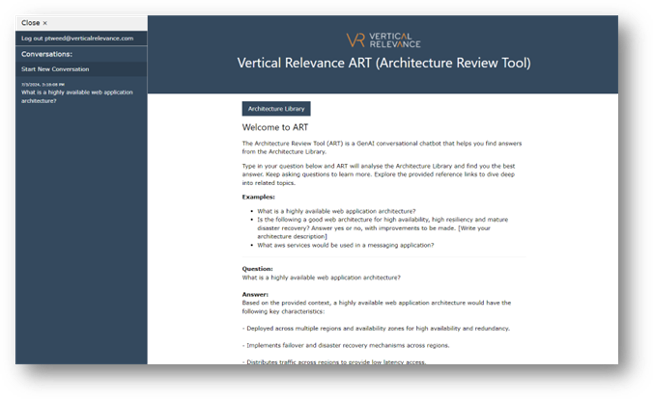
Figure-05
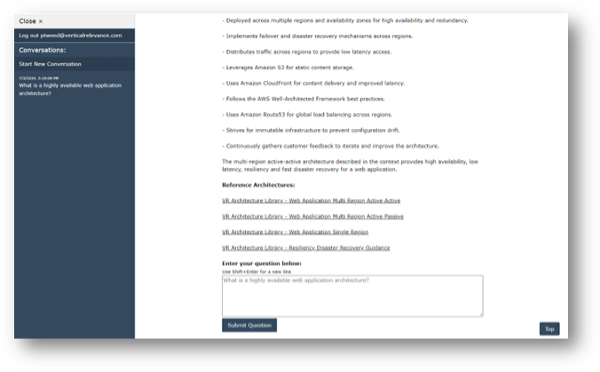
Figure-06
When a conversation is started, the first prompt submitted is recorded and displayed in a history list (most recent first) in the left-hand navigation pane, that can be closed by clicking on the “Close X” link expanded by clicking on the burger menu.

Figure-07
A user can choose to create a new conversation or continue an existing one by selecting it from the history list. When the user chooses a prior conversation, the entire conversation is loaded and displayed so the user can see the full history including the requests, answers and reference document links. The conversation is fed back in the context to the next request made. This allows the user to ask a series of ongoing questions or make requests within the same conversation, and ART will respond having referred to the prior conversation and the information sources available.
This is achieved in the Query Lambda using the Langchain ConversationalRetrievalChain module and storing each conversation and its history within a DynamoDB table.

Figure-08
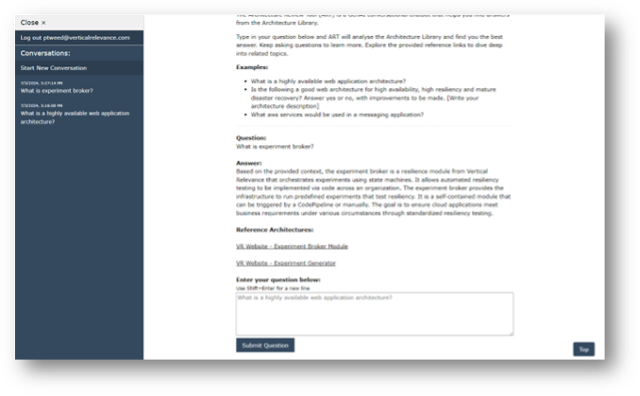
Figure-09
Security, Authentication, Authorization and RBAC
The conversational GenAI chatbot application is secure and requires that users register to access it. It also provides RBAC restriction to information sources based on the users access rights, determined from membership of Cognito groups. The authentication and authorization mechanisms can be swapped out to integrate with your company authentication and authorization systems. Every call to the Query, History and Context Lambdas validates authentication of a session token, so all information communication and access is secure.
Figure-10
All calls to the Lambda functions from single page application occur through Lambda Function URLs that provide a consistent secure endpoint for the lambda functions over TLS and refresh the content on the page based on their results.
The registration and login screens are provided by the Cognito Hosted UI. When a user wants to login, they are redirected to the Cognito Hosted UI, where they can follow the registration and account confirmation workflow or sign in if they have an already confirmed user account. Upon login, the application writes the Cognito session token to a cookie and both the cookie and the Cognito session expire in 24 hours.
When a user registers with ART following the Cognito registration and confirmation workflow, when they confirm their account after receiving a confirmation code to their email, the Add User To Group Lambda is triggered by Cognito and adds the new user to both Cognito groups: “VR-Architecture-Library” and “VR-Website”. If the system administrator wants to remove the user from one or both groups, they can go to the Cognito UI in the AWS Console and delete the association of the user with one or both Cognito groups.
Whenever a call is made from the single page application to the Query, Context or History Lambdas, the Cognito session token is provided as a bearer token. Within the lambda function the Cognito session token is validated to ensure the session is still active. If it is not, or if the token is not a valid token, or missing, the function returns with an appropriate response for the application to act on.
If the Cognito session token is valid, the email for the user is retrieved from the token as is the Cognito group membership for the user. The user’s email is used to retrieve and store DynamoDB records for History and Context.
Authorization through RBAC is implemented by verifying if the user has membership to one or more Cognito groups. If not, the request to the Query Lambda is denied. If so, the Query Lambda uses the Cognito groups to filter the document sources for the request submitted to only those information sources that match the name of the Cognito user groups for the user.
Examples of how this works:
- If user A is a member of the VR-Architecture-Library and the VR-Website user groups, when they submit a request, they will receive information back from both the Architecture Library and the Website information stores.
- If user B is a member of only the VR-Architecture-Library user group, when they submit a request, they will receive information back from only the Architecture Library information source and none from the Website information store.
- If user C does not below to either the VR-Architecture-Library or the VR-Website user groups, when they submit a request, they will receive a denied response as they don’t have access to any information stores.
Conversational Chatbot Prompt
The heart of the chatbot is the ability for the user requests to be processed through the Langchain modules with AWS Bedrock against the vector database. The core of the guidance on how Bedrock should evaluate the request is the prompt. The prompt used is:
prompt_template = """Use only the provided context to answer the question with a summary at the end. Answer using complete sentences. Do not provide incomplete sentences. If you don't know the answer, just say that you don't know, don't try to make up an answer. Don't include harmful content.
CONTEXT:
{context}
Question: {question}
Answer:""" The Langchain ConversationalRetreivalChain module combines the above prompt with the context for the conversation loaded from DynamoDB and the request provided by the user through the UI in the single page application, and then uses it to generate the answer.
Due to the way this is crafted, it allows simple questions to be asked and to have the chatbot evaluate input provided. In this way the user can submit a request such as:
Is the following a highly resiliency, low latency architecture with mature disaster recovery?
Answer yes or no and provide guidance to improve the architecture.
[Then provide the architecture description]
In this way, ART evaluates and provides guidance on the submitted written architectural description and provides guidance back to the user with reference links to architecture documents. This allows application teams to use ART to develop and iterate their AWS architectures and migration plans without scheduling rounds of meetings with senior architects and consultants. This allows them to fast track their migration design and planning work.
An example of an architecture description that does not meet the stated goals is shown below.
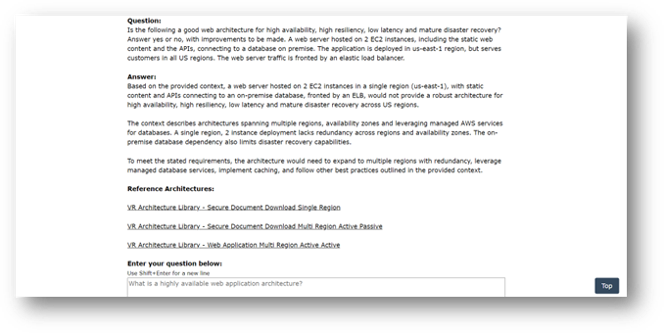
Figure-11
An example of an architecture description that meets the stated goals is shown below.

Figure-12
Extensibility
ART can have the information store(s) extended as you need for your use case(s), the authentication mechanism and the RBAC authorization replaced to meet you organization standards.
The RAG generative AI conversational chatbot solution can be applied to any knowledge domain(s) in your organization, from technology, to sales and marketing, to legal, HR, operations, or support. If you have an information source that you want an audience to be able to easily explore and gain guidance on, you can include the information source in the scope of the chatbot.
To extend the solution to include your own information stores you need to implement the following aspects:
- Extend the Create Document Database Python Module to execute the same process following the process identified in the Generation of the vector database. When you do so create a unique name for the information store, for the metadata associated with the document chunks created for the content in the information store.
- Extend terraform/website.tf resources to include a Cognito group named the same as the name given to the information store.
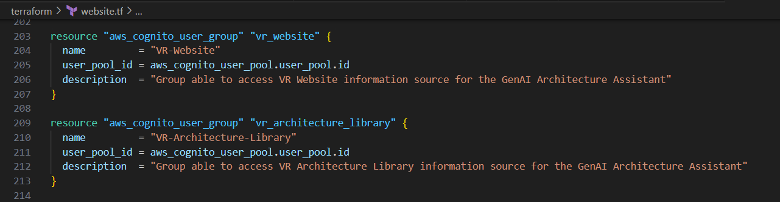
Figure-13
- Extend the Add User To Group Lambda logic to add newly registered and confirmed users to the new Cognito group, if you want users added automatically. Otherwise, you will need to create a manual process to add users to the new Cognito group once registered.
To change the authentication mechanism, you can easily swap in another OAuth 2.0 mechanism in the same way that Cognito Hosted UI works, or implement an alternate based on your enterprise standards. The aspects to change would be:
- Hook in the changed UI into the login and logout and session token cookie management functionality in the single page application.
- Update the Query, History and Context Lambda functions to implement the authentication checks for the JSON Web Token (JWT) OAuth 2.0 approach, or the equivalent authentication mechanism in your enterprise.
The RBAC authentication mechanism filters the documents included in the ConversationalRetrievalChain based on the Cognito groups for the user. If you wish to use an alternate approach you will need to identify the information stores the user should have access to, to provide in the filter to the ConversationalRetrievalChain.
Solution Mapping
ART provides a RAG generative AI conversational chatbot that can enable technology teams to learn about your AWS architecture library and gain feedback on their proposed architectures and migration approaches.
This allows them to work at their own pace, without being dependent on senior architects or consultants, whose time is expensive, and they can be hard to get engaged with depending on the demand on them.
| Problem | Solution |
| Guidance is only available through a bottlenecked architects and ARB | Teams can autonomously develop their architecture and migration approaches by using ART to gain guidance and links to appropriate architecture standards and have the chatbot evaluate their architecture to meet company standards. The team can schedule a final review or direct ARB review once their architecture is evaluated to meet their business goals and the company architecture standards. |
| Developing architectures and migration approaches is time consuming and costly | The team can work according to their own schedule and do not need to wait for senior architects and consultants to be available to understand their designs and provide them with feedback. The speed to develop architectures and migration approaches drastically reduces due to significantly lowered cycle times. Because the demand for senior architects and consultants is greatly reduced, the cost to create the architecture is also significantly reduced. |
| Strategic project opportunity cost | With the significant reduction of time demanded of senior team members, they are given back a lot of capacity to focus on strategic projects for the enterprise. This allows the parallel execution of business-critical projects on improving existing digital products and delivering new digital products or supporting other workstreams like acquisition integration, to be completed in parallel to migrations to AWS. This greatly reduces the opportunity cost associated with taking on AWS migrations. |
| Competing architecture guidance published within companies | Using RBAC access to information stores, users can be configured to have the right access to the right information through ART. This allows teams to efficiently discover the information, guidance and architecture standards that are appropriate to their line of business. |
Summary
ART provides a RAG generative AI conversational chatbot that allows teams to self-discover standards and guidelines and have their architectures and migration plans evaluated in an engaging manner at their own pace and at any time. This extensible platform can be expanded and focused on any information store, integrated with your own authentication mechanisms and RBAC authorization controls. When teams have completed their preparations, they can submit to the ARB for review. This significantly reduces the time and cost involved in developing your architecture and migration approaches for migration to AWS.
