Overview
Resilience and reliability of software systems are of critical importance; unplanned downtime and system failure not only impact revenue but can also undermine customer trust and loyalty. As businesses increasingly depend on complex systems, it is essential to implement rigorous testing to verify that applications can withstand unexpected disruptions. Doing so, however, requires significant resources and time, which organizations may not have. To help ease these requirements, we propose an AI-powered solution that accelerates the development of resiliency experiment code, allowing developers to do more in less.
Resiliency testing offers a valuable way to identify weaknesses. However, implementing these strategies is not easy. There is a high barrier of specialized expertise to even begin resiliency testing. In fact, many organizations forgo it entirely. For those that still do, many struggle to scale their efforts. Balancing the time and talent required against the vast and changing scope of resources is a persistent challenge. Indeed, when time is short many organizations will deprioritize resiliency, leaving critical vulnerabilities unaddressed.
To combat these challenges, we introduce Experiment Developer (ED), a GenAI approach to resiliency test code generation. ED develops actions and probes, the fundamental units that formulate a Chaos Toolkit experiment. For experiments to produce meaningful results, we need custom logic testing the unique features of each application. We do this application specific tailoring through python-based actions and probes (see Experiment Broker for more details on the use cases for actions and probes). Experiment Developer expands the breadth and depth of chaos testing coverage by generating the required python code to perform an experiment.
Further, our tool writes code with an emphasis on modularity, readability, and testability. Using advanced reasoning techniques and agentic RAG to interface with existing code bases, ED avoids reinventing the wheel and drafts high quality code that can take an action or probe 70-90 percent of the way to completion. This helps developers bring the code to the finish line with minimal effort.
Through our ED solution, development and SRE teams can use AI to accelerate resiliency efforts. A faster pace of development leads to a wider and more exhaustive scope of testing. More vulnerabilities can be caught and remedied leading to less unexpected outages, and ultimately, less revenue loss.
Prescriptive Guidance
Before diving into Experiment developer, it is important to acknowledge the following terminology.
Definitions
- LLM Model – Large language model, technology behind ChatGPT type apps. Works by ‘completing’ prompts
- Embedding Model – ML Model used to convert natural text into a vector, whilst retaining semantic meaning
- Hosted vs Self Hosted Models – self hosted models are models an organization builds and maintains themselves. Hosted models are models available through platforms like AWS Bedrock, OpenAI, etc.
- Vector Store – A database containing vectors and allowing for similarity search
- Chroma – Open source, in memory friendly vector store
- RAG – Retrieval Augmented Generation, a technique by which additional contextually relevant data is appended into an input prompt
- Chain of Thought – a technique that forces the LLM to think through and plan its responses
- AI Agent – an AI program that dynamically utilizes various data sources and tools for purposes of completing a specific task
- Langchain – an opensource library that helps interact with LLMs
- Experiment Broker – A VR solution that provides a platform for resiliency testing
- Chaos Toolkit – open-source chaos testing orchestrator that Experiment Broker is based on
- Actions – Chaos Toolkit term for a function meant to modify a system
- Probes – Chaos Toolkit term for a function meant to observe a system
- Experiments – a composition of actions and probes, expressed through a YAML template. An experiment maps onto a resiliency test case
Strategy
When faced with continually changing systems and software, developers will constantly need to write and upgrade their resiliency experiments. Often, new changes necessitate new actions and probes. Perhaps a new service demands a completely new library of experiments. Perhaps time is short. To better tackle these challenges, developers can make use of our Experiment Developer solution. Our tool uses AI and advanced reasoning techniques to write code drafts that cut development time down to about a quarter of usual rates.
Experiment Developer is composed of three components: Consumption (usage), Generation (core development logic), and ingestion (data processing). This solution focuses primarily on generation and ingestion. For consumption, we include a simplified front end UI. Typically, for the UI, we try to integrate with already existing frameworks in the customer environment.
To illustrate how these 3 components work together to develop new experiment python functions, let’s follow an example. A developer has written a new feature for his application that includes SQS – an AWS resource they have not previously used. He needs to expand his testing framework to be able to perform SQS experiments and has identified an Action and several Probes that need to be developed. He goes to the UI, the Consumption component, where he provides the 3 necessary inputs (name, purpose and services) for the first probe. Once the developer hits submit, the front-end sends an API call that begins the Generation component, the core logic that develops the python code.
During Generation, Experiment Developer will map out a development plan and iteratively write the function code. The development plan is contextually aware of any available codebases by virtue of the Ingestion component. Ingestion handles creating and updating the data stores (vectorized code bases) that helps Experiment Developer avoid writing redundant code. Experiment Developer then uses an iterative approach to write out the requested probe. Once complete, the code is returned to the developer, who can then make edits as necessary. Finally, once the developer PR’s the code into the main branch, the Ingestion component gets triggered in the background and updates the data in the Vector Store with the new code, preparing it for the next time Experiment Developer runs.
For more details on what each Component is doing see the details below.
Generation
As the name implies, generation handles the core code generation. This stage begins when a request is received and passed into the Fargate container for processing. ED takes an iterative approach to code development, making use of techniques such as chain of thought, RAG, and prompt chaining.
The reasoning workflow for generation follows a largely sequential approach, with each LLM call building upon the previous one. Usually, this process takes 7 to 15 calls to etch out the final output. It begins with the ED agent creating a high-level, step-by-step development plan based on the user input. This plan helps clarify the exact requirements for the desired function. This plan is not the final plan, however. This first plan serves as a search query for running a similarity search on the vector store. We found this approach of generating a plan from the user inputs and using it as the search string to be superior to simply using the user input directly. The purpose of the search is to identify code (functions) we can reuse from our code base, enabling ED to avoid writing redundant code.
Once we have a candidate pool of reusable functions, we have the LLM rewrite the development plan, this time with an aim on reusing some of the functions we have at hand. Additionally, this step outputs a development plan where each step maps to a subfunction, with our reusable functions filling in certain steps. The next stage generates the non-reusable subfunctions.
The subfunctions are generated sequentially in a three-step process. First, like the broader function, the LLM creates a high-level implementation plan. Second, it uses that plan to write the code. Third, the LLM conducts a code review of the generated code. After these three steps, the subfunction is judged complete. Note, this stage is done in sequence but can be parallelized should time be a concern.
Once all the subfunctions are complete, the final LLM call ties everything together to create the main function. The final call also generates some usage notes and a sample chaos toolkit YAML snippet. Experiment Developer wraps up with some logic-based post processing and posts the update into DynamoDB for storage, from which users may pull their code from. In this manner, we end up with a highly modular function that seamlessly integrates with our experiment library.

Figure-01
Ingestion
The purpose of ingestion is to create and update the vector stores used in generation. The process depends on the target. For code base vectorization, it follows a GitOps flow; the trigger is a git commit. Once a change is pushed to a repo tracked by the CICD process (we used GitHub, CDK Pipelines, and AWS CodeBuild/CodePipeline), the change goes through a diff check to evaluate what if, any, files must be updated in the vector store. The ingestion logic will only trigger if a change is detected.
The ingestion logic runs on the same container as generation but has a separate CLI level entry point differentiating its workflow. The process transforms the input data into a format suitable for vector search. For raw code, we found vector search returns the best results when embedding (AI generated) summarizations of the code, rather than directly embedding a code snippet.
Once the embedding process is complete, ED uploads the embeddings to the vector database. For our database, we used Chroma, which works in-memory and is suitable at limited scale. Our Chroma database is serialized and persisted in S3, from where the generation workflow can pick it up.
Consumption
Experiment Developer can be used through any interface capable of making API calls. We include a simple form based front end written in Typescript and React. Other approaches include IDE plugins, full on chat interfaces, or low code UI integrations. In fact, to maximize Experiment Developers efficiency, a guided chat may be the best option. This would allow for optimizations like targeted regeneration, user-based tree of thoughts generation, and AI guided brainstorming.
Best Practices / Design Principles
Choice of Model
The model has a significant impact on quality and cost. For our agentic flow, we need an LLM model capable of function calling, or at minimum, reliable output structuring. Our solution uses hosted models (i.e. OpenAI, Bedrock, Claude) and is relatively model agnostic. We recommend either OpenAI GPT 4 or Claude Sonnet 3.5.
Some organizations may want to use self-hosted models. The advantage of self-hosted models is that the organization has full control over it, making things like fine tuning and RLHF (reinforcement learning with human feedback) a future possibility. In this case, our solution can be refitted in that direction.
Choice of Vector Store
There are a variety of vector storage options to choose from. For our purposes, choosing the correct one depends largely on the expected scale. We will largely vectorize codebases and potentially documentation and other relevant data sources. For vector stores of limited scale, we recommend implementing an in-memory vector database serialized and persisted on S3. We found Chroma to be a good choice.
If we envision our vector count going over about 10-20 thousand vectors and response times become relevant (our current format is async), then we recommend considering more dedicated vector stores like AWS OpenSearch.
Input Params Best Practices
Experiment Developer is best seen as a force multiplier. The quality of input it receives correlates with the quality of output. Zero times zero is in fact zero. If the input is poor the output will also be poor.
Our input consists of three parameters: name, purpose, services. Of these, most important is the purpose. It need not be very long; one or two sentences is sufficient. For someone who knows the environment well and has a clear intention for what the action/probe should do, writing the purpose should be simple. In general, we recommend being as specific and clear as possible. Further, clarifying expected inputs and outputs for the function will yield higher quality results.

Figure-02
Data Sources
Currently our principal data source is a vectorized code base housing the actions and probes. We use our custom Experiment Broker resiliency testing library, though our solution can integrate any number of open-source chaos testing libraries.
In addition, Experiment Developer has capacity to integrate any other types of data such as documentation, API contracts, and infrastructure templates. These additional data sources can help inform and improve the AI generated code. Nonetheless, we have found simply having a vectorized codebase very satisfactory.
Security Concerns
To control access to Experiment Developer we primarily use the API resource policy. Access can be scoped down to VPC endpoints or IP address. To further control access, it’s possible to implement AWS Cognito or a custom authorization method.
In regards of the LLM itself, the main concern security teams might have been what data is being shared with the model providers. In the case of a self-hosted model, this is obviously not a concern as the organization owns and hosts its own model. But for hosted models, code and documentation data pertaining to the systems subject to testing are likely to be sent along an LLM prompt.
For Amazon Bedrock, see Data protection – Amazon Bedrock. The core promises here are that Bedrock “doesn’t store or log your prompts and completions. Amazon Bedrock doesn’t use your prompts and completions to train any AWS models and doesn’t distribute them to third parties.” Models are further isolated into a “Model Deployment Account”, which model providers also lack access to.
Cost and Usage
Experiment Developer generations typically cost between 5-10 cents under most of the latest models. Time to complete ranges between 2-5 minutes. The main method to control cost and speed is model choice. Additionally, if speed is a concern, there are certain code level concurrency changes we can make. Migrating to a containerized lambda is another option to speed up response times.
Experiment Developer

Figure-03
Experiment Developer is composed of three parts: generation, ingestion, and consumption. Our solution builds out the generation (reasoning workflow) and ingestion (vectorization workflow) parts, whilst the consumption model (UI) is flexible, and we typically choose to integrate with any already existing frameworks in the customer environment. On the infrastructure side, Experiment Developer is serverless and is designed to run async, though it does have potential to work in a more synchronous, chatbot environment.
Components
- Fargate/ECS – Main compute platform where our logic will run. Our ingestion and generation logic run in the same container, but with different CLI entry points
- API Gateway – Entry point for user access of the tool. Frontend will hit this API
- Lambda – Backend for API Gateway. We use a proxy integration as our integration is not super complex
- S3 – Storage, mainly for serialized vector database and code that will be ingested into the vector database.
- EventBridge – watches S3 for code changes and triggers vectorization workflow
- DynamoDB – Storage for all code generations, as well as supporting details and tracking
- ECR – Used for container management
- VPC – required for ECS
- CDK Pipelines/CodeBuild – Handles CICD as well as git tracking, which conditionally triggers the ingestion workflow
How it works
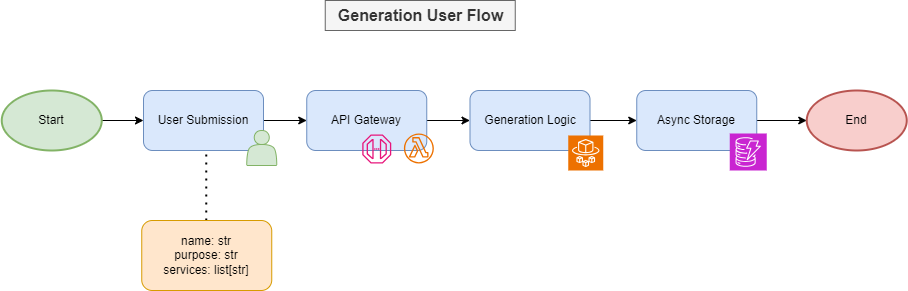
Figure-04
Generation
Generation starts with the user. Once the user submits the input parameters through a post API call to the API Gateway, the generation workflow begins. The API Gateway uses a Lambda Proxy integration to process all requests. A post call to /generation will trigger the Fargate container running the core generation logic. A get call will get generated output data from DynamoDB.
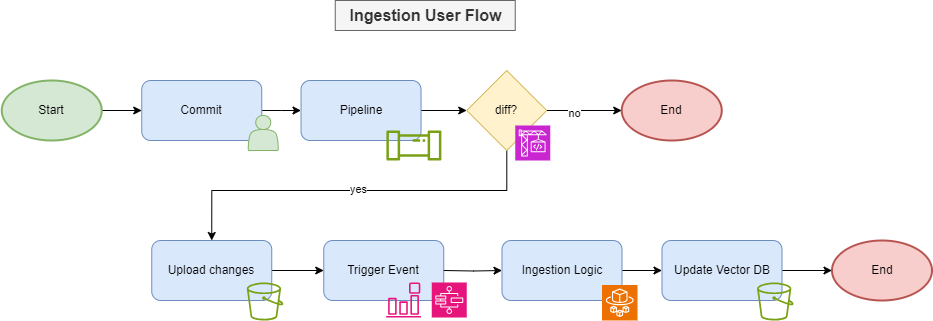
Figure-05
Ingestion
Ingestion follows a GitOps pattern, wherein a git commit on a tracked branch triggers the workflow. All changes will be examined via a script running on AWS CodeBuild. The script will run a git diff and find relevant changes, which it will then push to S3. An EventBridge rule will than trigger the ingestion logic. Finally, the ingestion logic updates the vector database and completes the workflow.
Blueprint
The GitHub repo is here
Benefits
- ED delivers code 70-90 percent of the way to completion allowing faster pace of development
- ED easily integrates with existing codebases and avoids writing repetitive code
- Flexible design that can be molded to specific customer needs
End Result
The ultimate goal of this solution is to increase the scale and scope of resiliency testing, allowing organizations to validate the reliability of their systems, avoiding sudden and costly failure down the lane.
