The term Disaster Recovery (DR) is enough to keep both engineers and executives up at night. Any event that can have a negative impact on your business continuity could be characterized as an adverse event. This is especially true for large financial institutions running hundreds if not thousands of workloads across multiple different environments and infrastructures. While well-designed architectures, consistently executed gamedays, and well-documented runbooks can all aid an organization’s resiliency when faced with a DR situation, much of this only applies to infrastructure within their control. While AWS provides various features and services that you can leverage for your DR processes you have to take in consideration the shortcomings and occasional, but often widespread outages and be prepared ahead of time.
Background
In this blog post, we will discuss the fundamentals of implementing an automation framework around disaster recovery so you too can improve your DR plan. Large Financial Services institutions across the industry must meet specific resiliency compliance to withstand events that could disrupt their businesses. Given the potential implications of downtime of services within the financial services space, the tolerance for downtime is in many cases, near-zero RPO and RTO.
Precautions can be taken to avoid DR events for infrastructure within an organization’s control; however, what about circumstances outside of an organization’s control such as when there is a region or AWS service failure? How does one determine if there is a region or AWS service failure? Lastly, what automations can be applied in this space to not only detect, alert but also remediate in the event of such a failure?
As if an application’s availability requirements were enough of a challenge for financial services institutions, additional challenges arise. The table below defines several problems a financial services institution can face and must consider when seeking to automate DR activities.
| Problem | Details |
| Tight RTO / RPOs for Critical Apps | Many front office applications have very strict requirements for RTO / RPOs of said applications to ensure that their applications are available and meeting expectations in place by internal BUs and other external partners. |
| Hybrid Architecting and Architecture | Many applications within the financial services spaces operate in a hybrid architecture. Adoption of the cloud is picking up in the industry but has still seen a slower rate of adoption than other areas which results in infrastructure being both on-premise and in the cloud. |
| AWS Service Level Accountability | Architectures can be designed to be resilient, but if a core service within AWS goes down, it is outside of the customer’s control. Monitoring and alerting for said service outages is a must. |
| Legacy Hardware and Software | Many applications leveraged within financial services rely on legacy technologies and programming languages such as Cobal or mainframes. Prior to leveraging the cloud, refactoring / re-architecting is oftentimes required. |
Before diving into the aspects of automation, let’s first discuss the different levels of infrastructure failure an organization may experience with a DR event. The below table lists the types of AWS failures one could experience.
AWS Failure Types
| Outage Type | Description | Example | Impact Level |
| Region | The region is being impacted in a critical way where more than one service is not performing as expected and is causing impact on the workload availability. | us-east-1 | High |
| AWS Service | An AWS service(s) within a region is not operating properly and is impacting workloads running on that service. | Elastic Kubernetes Service | High |
| Availability Zone | A single availability zone in a region is being impacted. Resources deployed in that AZ may be impacted. | us-east-1d | Medium / High |
| Resource | An individual resource stops operating properly (ex. EC2 instance failure) which can affect workload availability depending on architecture design. | EC2 Instance | Low / Medium |
Solution
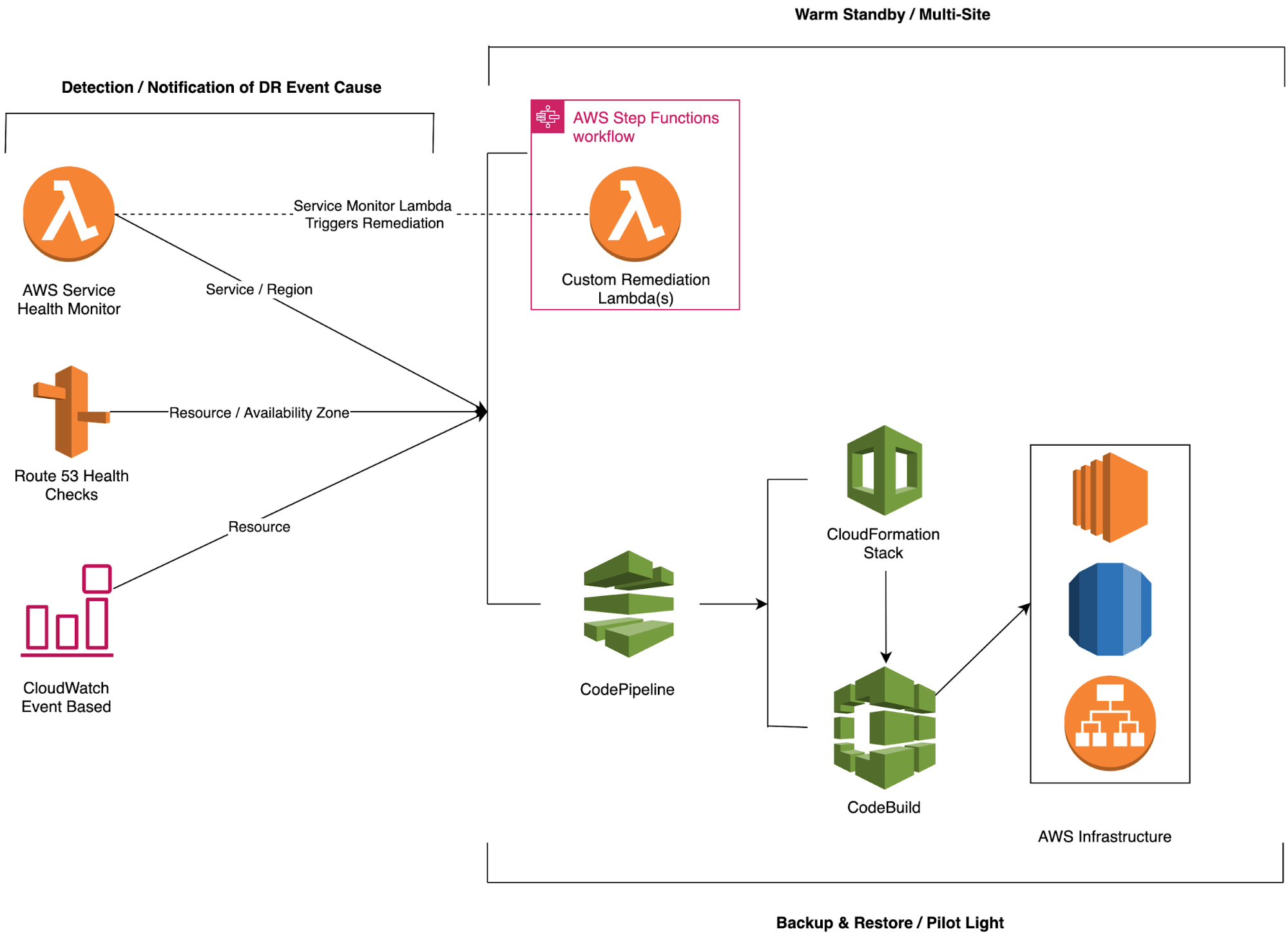
As discussed in the prior section, any event that can negatively impact your business continuity could be named a disaster. Planning for Disaster Recovery is one of the most important use cases enterprises look to achieve. The question becomes where to start? As shown in Figure – 02 we discuss the four major ways in which an outage within AWS can occur. Figure – 03 aims to address the four variations of outages and propose solutions to not only detect but also automatically remediate. An example and solution for each outage type have been detailed below.
** Note this solution was developed purely as a proof of concept. The code presented below was not ported into lambda functions but could easily be done if desired.
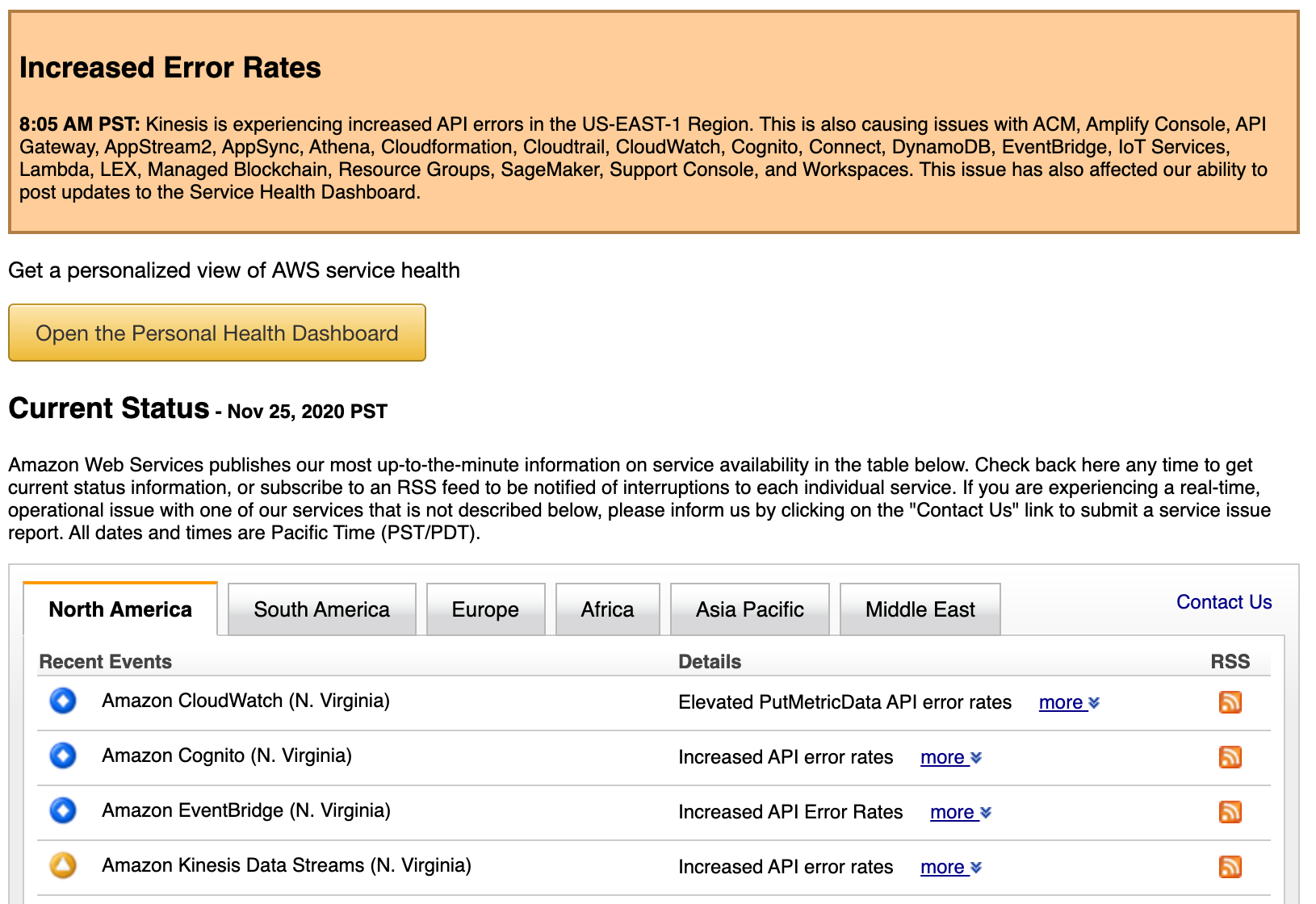
Before we dive into the solution details, let’s first start by seeing the AWS Service Health Check in action!
Region / Service Failure
What is a region failure and how do you detect one?
While this may seem rather straightforward upon initial ask, the truth of it is that a region failure means different things to different organizations. Is it considered a region failure if a core AWS service within the region goes down? Does it need to be multiple services that are affected? What if it’s a service you’re not leveraging, but the region is still experiencing availability issues? The true definition of a region failure needs to be defined by an organization and the workloads that they are running. In some cases, what might be a region failure for one workload, is not a region failure for another as they depend on different services.
The point being that region failures are not black and white like one may think. To complicate the situation further, we move on to addressing how do you detect a region failure? Funny enough, there isn’t some toggle or direct API query that can be made to determine if there is a region failure/outage. The reason behind this is because AWS will rarely, if ever, acknowledge that they’re having a failure at the scale of an entire region. It’s much more likely that they’ll denote affected services within a region.
Service Levels
While any service outage within AWS can prove to be disruptive, there are services within a workload that are more critical than others. The tool allows the end-user to classify services by three categories depending on the level of criticality to the workload. There are three levels of services that are detailed below.
- Platinum Service
- Services critical to your existing architecture and workload. Availability issues affecting a singular critical services result in a defined failover action and notification.
- Gold Service
- Services that are non-essential to your existing production architecture and workload, but if failed would result in sub-optimal operating conditions.
- Silver Service
- Auxiliary services within architecture and workload. Have no functional or operational impact on existing workload. Losing these services will not result in any sort of resiliency event but will result in a notification.
If any of the platinum services are down, it is considered a DR event and proper notification and in some cases, remediation will be triggered. There are additional settings that can be specified to define one’s tolerance for failures among the gold and silver tiers as well that will cause a DR event.
As stated previously, the tool leverages an INI input file to determine the services that are being leveraged in a workload. To see a complete list of the services that that Health API currently monitors the following query can be executed. Note that the query will return duplicates.
aws health describe-event-types --region us-east-1 --query 'eventTypes[*].[service]'
After determining the services that are relevant in a workload, they can be passed into the configuration file. To generate a configuration file with relevant services, make a copy of this Google Sheet and define the service level for each individual service. An example configuration file has been included below.
[default]
platinum_services=APIGATEWAY,AUTOSCALING,CLOUDFRONT,DIRECTCONNECT,EBS,EC2,ELASTICFILESYSTEM,EKS,ELASTICLOADBALANCING,INTERNETCONNECTIVITY,LAMBDA,NATGATEWAY,RDS,ROUTE53,ROUTE53PRIVATEDNS,ROUTE53RESOLVER,S3,SNS,TRANSIT_GATEWAY,VPC
gold_services=BACKUP,CLOUDFORMATION,EVENTS,IAM,GLACIER,SECRETSMANAGER,SECURITYHUB,SSM,CLOUDWATCH
silver_services=ATHENA,BILLING,ACM,CHIME,CLOUDTRAIL,CODEARTIFACT,CODEBUILD,CODECOMMIT,CODEDEPLOY,CODEPIPELINE,CODESTAR,CONFIG,CONTROLTOWER,GUARDDUTY,MANAGEMENTCONSOLE,MARKETPLACE,ORGANIZATIONS,HEALTH,SSO,SUPPORTCENTER,TAG,TRUSTEDADVISOR,WELLARCHITECTED
allowed_gold_failures=2
allowed_silver_failures=4
region=us-east-1
dynamodb_table_name=poc_aws_failure_events
[notifications]
platinum_sns_arn=arn:aws:sns:us-east-1:XXXXXXXXXXXX:poc_vr_aws_health_platinum_services_failure
gold_sns_arn=arn:aws:sns:us-east-1:XXXXXXXXXXXX:poc_vr_aws_health_gold_services_failure
silver_sns_arn=arn:aws:sns:us-east-1:XXXXXXXXXXXX:poc_vr_aws_health_silver_services_failure
The tool’s logic flow as well as other aspects of the tool can be shown in Figure – 05 below.
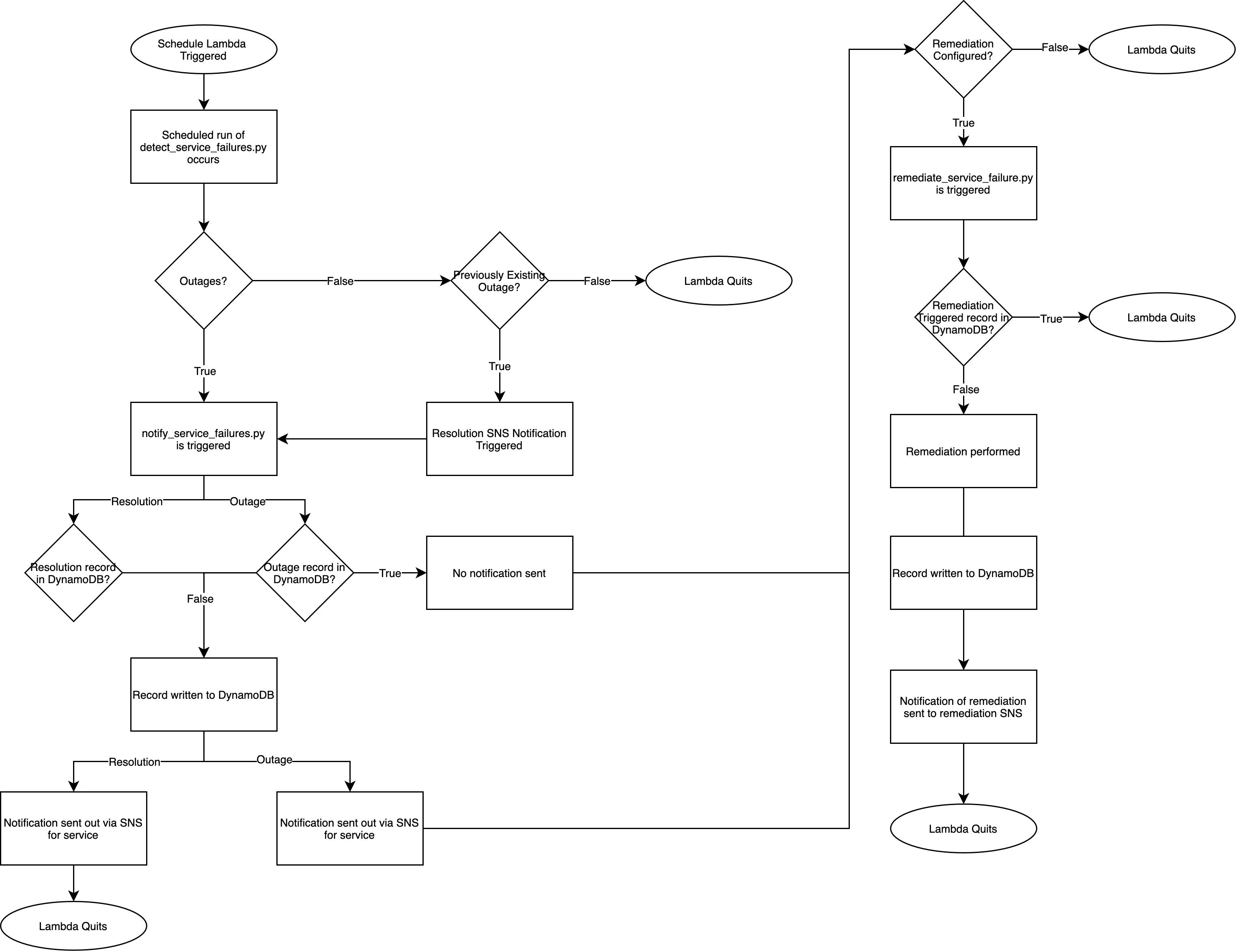
Tool Execution
When the tool executes it looks for any of the specified services within the configuration file that are either down or were previously down. When a service is detected as down, the record of the outage is written to the designated DynamoDB Table as seen below.
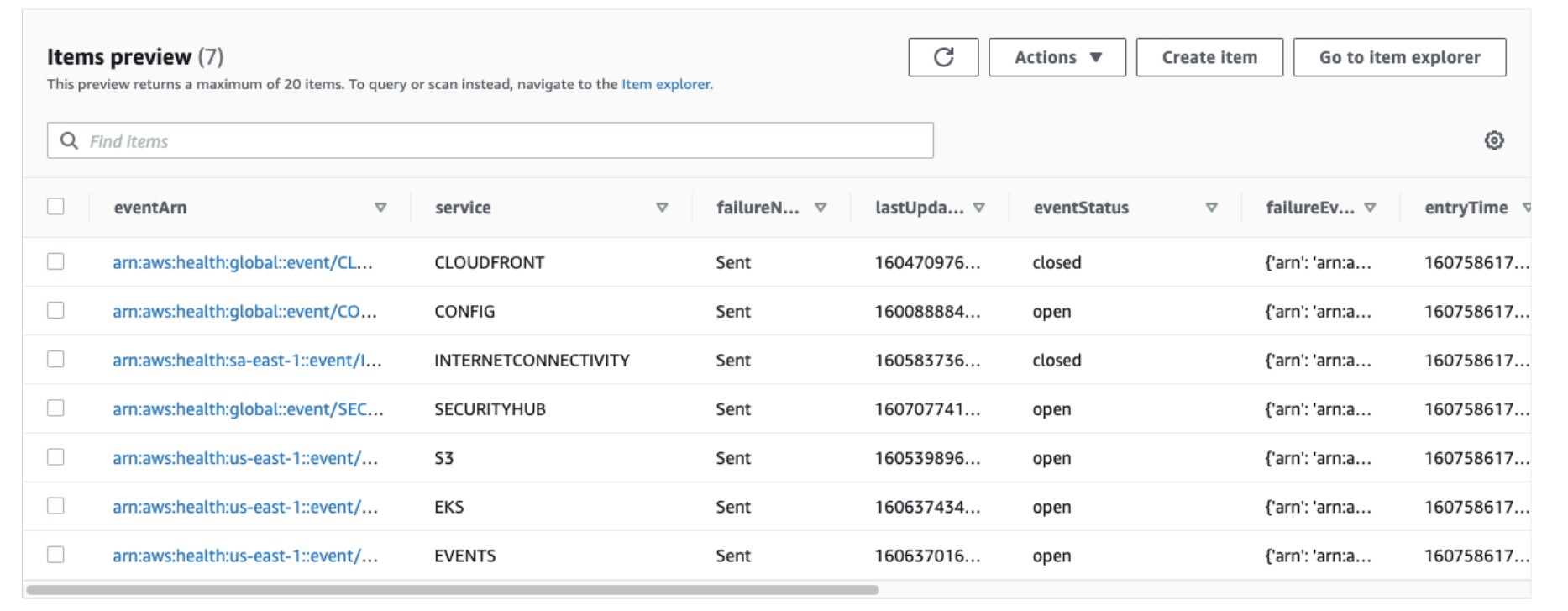
| eventArn | arn:aws:health:global::event/CLOUDFRONT/AWS_CLOUDFRONT_OPERATIONAL_ISSUE/AWS_CLOUDFRONT_OPERATIONAL_ISSUE_MWZEU_1604706910 |
| service | CLOUDFRONT |
| failureNotificationStatus | Sent |
| resolutionNotificationTimestamp | 1607586224 |
| outageStartTime | 1604706910 |
| failureEventString | {‘arn’: ‘arn:aws:health:global::event/CLOUDFRONT/AWS_CLOUDFRONT_OPERATIONAL_ISSUE/AWS_CLOUDFRONT_OPERATIONAL_ISSUE_MWZEU_1604706910’, ‘service’: ‘CLOUDFRONT’, ‘eventTypeCode’: ‘AWS_CLOUDFRONT_OPERATIONAL_ISSUE’, ‘eventTypeCategory’: ‘issue’, ‘region’: ‘global’, ‘startTime’: 1604706910.376, ‘endTime’: 1604709763.994, ‘lastUpdatedTime’: 1604709764.168, ‘statusCode’: ‘open’, ‘eventScopeCode’: ‘PUBLIC’} |
| entryTime | 1607586179 |
| failureNotificationTimestamp | 1607586179 |
| resolutionNotificationStatus | Sent |
| eventStatus | closed |
| serviceLevel | Platinum |
| outageEndTime | 1604709764 |
| lastUpdateTime | 1604709764 |
| associatedSnsTopic | arn:aws:sns:us-east-1:899456967600:poc_vr_aws_health_platinum_services_failure |
A notification about the outage is also sent out to the SNS topic subscribers alerting them of the outage.
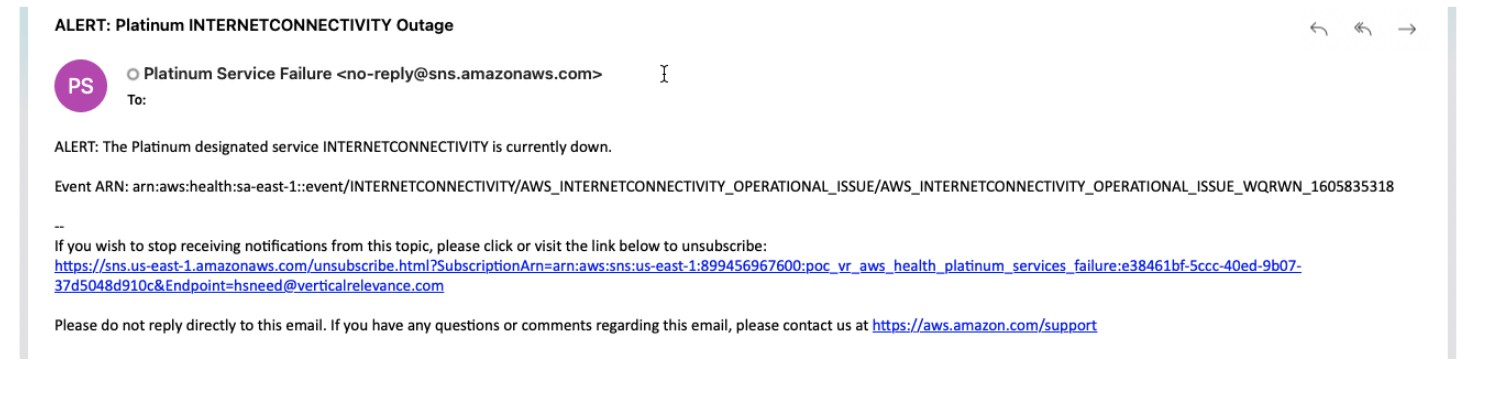
Upon restoration of the failed service(s), a notification will be sent to the SNS topic subscriber saying that the service outage has ended.
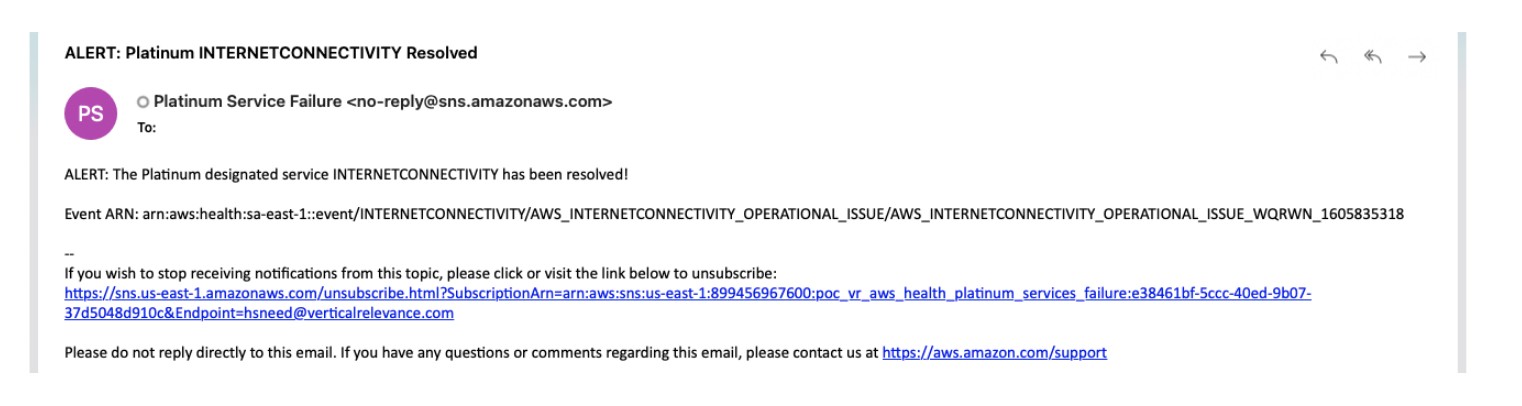
Beyond detection and notification, a custom remediation can also be triggered from within the tool based on the service that has failed. Given the unique architecture and requirements of a workload, the remediation functionality is only intended to trigger a remediation external to the tool using something like AWS Step Functions or AWS CodePipeline.
The tool has been broken up into three separate scripts that all function as a single lambda.
detect_service_failures.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
'''Return the status of specified AWS Services'''
import logging
import configparser
import json # for testing purposes only to read in test file
import boto3
# Setting up logging component of lambda script
logging.basicConfig(level=logging.WARNING)
# Creates up config parser object and imports the config file
config = configparser.ConfigParser()
config.read_file(open('./aws_service_config.ini'))
logging.info("Input file loaded successfully")
# Creates boto3 health needed for script
health_client = boto3.client('health')
def get_service_level(service):
if service in config['default']['platinum_services'].split(","):
return("Platinum",config['notifications']['platinum_sns_arn'])
if service in config['default']['gold_services'].split(","):
return("Gold",config['notifications']['silver_sns_arn'])
if service in config['default']['silver_services'].split(","):
return("Silver",config['notifications']['silver_sns_arn'])
# Detection Functionality
# #### FOR TESTING ONLY - READING IN FILE FOR SAMPLE EVENTS ####
# with open('test_health_events_payload.json') as f:
# health_response = json.load(f)
def detect_service_failures():
### Need to run as root account for this to work
#health_response = health_client.describe_events_for_organization()
# Get recent health events that are open for account lambda resides in
health_response = health_client.describe_events(filter={
'regions': [
(config['default']['region']).strip('"')
],
'eventStatusCodes': [
'open'
],
}
)
logging.info("Successfully checked for failed services")
# Creating empty list to store possible failed services in
if len(health_response['events']) == 0:
logging.info("There are no current AWS Health Events - EXITING")
return
else:
logging.info("There are AWS health events affecting your account")
# Creating a dictionary object that stores the different service level and failed service
service_failure_dict = dict()
# Creating a dictionary object that stores the full failure event inside
event_failure_dict = dict()
for i, event in enumerate(health_response['events']):
try:
# Check platinum specified services for failures
if get_service_level(event['service'])[0] == "Platinum":
logging.info((f"{event['service']} is a platinum service and has degraded health"))
service_failure_dict.setdefault("Platinum", []).append(event['service'])
event_failure_dict[event['arn']] = event
# Check gold specified services for failures
if get_service_level(event['service'])[0] == "Gold":
logging.info((f"{event['service']} is a gold service and has degraded health"))
service_failure_dict.setdefault("Gold", []).append(event['service'])
event_failure_dict[event['arn']] = event
## Check silver specified services for failures
if get_service_level(event['service'])[0] == "Silver":
logging.info((f"{event['service']} is a silver service and has degraded health"))
service_failure_dict.setdefault("Silver", []).append(event['service'])
event_failure_dict[event['arn']] = event
logging.info("Successfully returned dictionary with failed services")
except TypeError as NotCriticalService:
pass
# Returns failed items and events to a dict that can be passed into notify function
return (service_failure_dict, event_failure_dict)
detect_service_failures()
notify_service_failures.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''Return notification of specified AWS Services'''
import logging
import configparser
import botocore.exceptions
import boto3
import time
from detect_service_failures import detect_service_failures, get_service_level
# Setting up logging component of lambda script
logging.basicConfig(level=logging.DEBUG)
# Creates up config parser object and imports the config file
config = configparser.ConfigParser()
config.read_file(open('./aws_service_config.ini'))
logging.info("Input file loaded successfully")
sns_client = boto3.client('sns')
dynamno_db_client = boto3.client('dynamodb')
# Check DynamoDB for record of outage
# If outage, check if ARN exists in Dynamo. If it exists, don't write. If it doesn't exist, write it.
def write_service_failure_event(event_failure_dictionary):
for event in event_failure_dictionary:
try:
if event_failure_dictionary[event]['statusCode'] == "open":
dynamo_put_response = dynamno_db_client.put_item(
TableName= config['default']['dynamodb_table_name'],
Item={
'eventArn': {'S': event_failure_dictionary[event]['arn']},
'service': {'S': event_failure_dictionary[event]['service']},
'serviceLevel': {'S': get_service_level(event_failure_dictionary[event]['service'])[0]},
'outageStartTime': {'S': str(event_failure_dictionary[event]['startTime'])},
'entryTime': {'S': str(time.time())},
'outageEndTime': {'S': 'N/A'},
'lastUpdateTime': {'S': str(event_failure_dictionary[event]['lastUpdatedTime'])},
'failureNotificationStatus': {'S': 'Upcoming'},
'failureNotificationTimestamp': {'S': "TBD"},
'resolutionNotificationStatus': {'S': 'N/A'},
'resolutionNotificationTimestamp': {'S': 'N/A'},
'associatedSnsTopic': {'S': str(get_service_level(event_failure_dictionary[event]['service'])[1])},
'failureEventString': {'S': str(event_failure_dictionary[event])},
'eventStatus': {'S': event_failure_dictionary[event]['statusCode']},
'remediationActionStatus': {'S': 'N/A'},
'remediationActionTimestamp': {'S': 'N/A'},
},
ReturnValues='ALL_OLD',
ReturnConsumedCapacity='INDEXES',
ConditionExpression="attribute_not_exists(eventArn)",
)
# Calls function right after sending notification so record can be updated
event_open_update_notification(event_failure_dictionary[event])
# Checks if event has been closed since last run, if so, it calls the event closed function and sends notification
if event_failure_dictionary[event]['statusCode'] == "closed":
closed_response = dynamno_db_client.get_item(
TableName=config['default']['dynamodb_table_name'],
Key={
"eventArn": {"S": event_failure_dictionary[event]['arn']},
"service": {"S": event_failure_dictionary[event]['service']}
},
)
if 'Item' in closed_response and "'resolutionNotificationStatus': {'S': 'Sent'}" not in str(closed_response['Item']):
event_closed(event_failure_dictionary[event])
except botocore.exceptions.ClientError as e:
pass
def event_open_update_notification(event):
if event['statusCode'] == "open":
try:
send_event_open_notification(event)
update_item_response = dynamno_db_client.update_item(
TableName=config['default']['dynamodb_table_name'],
Key={
'eventArn': {'S': event['arn']},
'service': {'S': event['service']},
},
ReturnValues= 'ALL_NEW',
ReturnConsumedCapacity='INDEXES',
UpdateExpression='SET failureNotificationStatus = :updatedfailureNotificationStatus, failureNotificationTimestamp = :updatedfailureNotificationTimestamp',
ConditionExpression = "eventStatus = :eventStatus AND failureNotificationStatus = :failureNotificationStatus AND failureNotificationTimestamp = :failureNotificationTimestamp",
## Conditional for status code = open and failureNotificationStatus and failureNotificationTimestamp
ExpressionAttributeValues={
":failureNotificationStatus": {'S': 'Upcoming'},
":failureNotificationTimestamp": {'S': 'TBD'},
":updatedfailureNotificationStatus": {'S': 'Sent'},
":updatedfailureNotificationTimestamp": {'S': str(time.time())},
":eventStatus": {'S': 'open'},
},
),
except botocore.exceptions.ClientError as e:
pass
def event_closed(event):
try:
send_event_closed_notification(event)
close_item_response = dynamno_db_client.update_item(
TableName=config['default']['dynamodb_table_name'],
Key={
'eventArn': {'S': event['arn']},
'service': {'S': event['service']},
},
ReturnValues= 'ALL_NEW',
ReturnConsumedCapacity='INDEXES',
ConditionExpression = "eventStatus = :eventStatus",
UpdateExpression='SET lastUpdateTime = :updatedLastUpdateTime, resolutionNotificationStatus = :updatedresolutionNotificationStatus, resolutionNotificationTimestamp = :updatedresolutionNotificationTimestamp, eventStatus = :updatedEventStatus, outageEndTime = :updatedEndTime',
## Conditional for status code = open (needs to be updated to closed)
ExpressionAttributeValues={
":updatedEndTime": {'S': str(event['endTime'])},
":updatedLastUpdateTime": {'S': str(event['lastUpdatedTime'])},
":updatedresolutionNotificationStatus": {'S': 'Sent'},
":updatedresolutionNotificationTimestamp": {'S': str(time.time())},
":eventStatus": {'S': 'open'},
":updatedEventStatus": {'S': 'closed'},
},
),
except botocore.exceptions.ClientError as e:
pass
def send_event_open_notification(event):
# Created a variable that can be used to reference sns topic arn in input config
sns_selection = get_service_level(event['service'])[1]
service_level = get_service_level(event['service'])[0]
# Conditional to only send out notification if SNS ARN for service level isn't ""
if sns_selection != '""':
# Sends out SNS notification to all subscribers on list
sns_open_response = sns_client.publish(
TopicArn=sns_selection,
Message=(f"ALERT: The {service_level} designated service {event['service']} is currently down.\n\nEvent ARN: {event['arn']}"),
Subject=(f"ALERT: {service_level} {event['service']} Outage"),
)
def send_event_closed_notification(event):
# Created a variable that can be used to reference sns topic arn in input config
sns_selection = get_service_level(event['service'])[1]
service_level = get_service_level(event['service'])[0]
# Conditional to only send out notification if SNS ARN for service level isn't ""
if sns_selection != '""':
# Sends out SNS notification to all subscribers on list
sns_closed_response = sns_client.publish(
TopicArn=sns_selection,
Message=(f"ALERT: The {service_level} designated service {event['service']} has been resolved!\n\nEvent ARN: {event['arn']}"),
Subject=(f"ALERT: {service_level} {event['service']} Resolved"),
)
write_service_failure_event(detect_service_failures()[1])
remediate_service_failures.py – still a few changes pending
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''Remediate specified AWS Services'''
import logging
import configparser
import botocore.exceptions
import boto3
import time
from detect_service_failures import detect_service_failures, get_service_level
from notify_service_failures import write_service_failure_event
# Setting up logging component of lambda script
logging.basicConfig(level=logging.INFO)
# Creates up config parser object and imports the config file
config = configparser.ConfigParser()
config.read_file(open('./aws_service_config.ini'))
logging.info("Input file loaded successfully")
# Creates boto3 health needed for script
health_client = boto3.client('health')
dynamno_db_client = boto3.client('dynamodb')
sfn_client = boto3.client('stepfunctions')
lambda_client = boto3.client('lambda')
codepipeline_client = boto3.client('codepipeline')
'''
This script is intended to be customized based on individual use cases for how to handle certain service outages.
Below I've included a sample function that checks if an issue is open and it pertains to a select service.
If so, it executes the code below and also updates the dynamodb table to indicate that the remediation has been triggered
'''
def remediate_SERVICE(event_failure_dictionary):
for event in event_failure_dictionary:
if event_failure_dictionary[event]['statusCode'] == "open" and event_failure_dictionary[event]['statusCode'] == "SERVICE":
pass
# Custom Remediation Code Here
# Calling a custom lambda remediation
# remediate_SERVICE_response = lambda_client.invoke(
# FunctionName='Remediation-Lambda',
# InvocationType='Event',
# Payload='Remediation-Payload',
# )
# Kicking off a codepipeline / step function
# remediate_SERVICE_response = sfn_client.start_execution(
# stateMachineArn='arn:aws:states:us-east-1:123456789012:stateMachine:remediate-service',
# name='Remediate-Serivce',
# input='sample-header'
# )
# remediate_SERVICE_response = codepipeline_client.start_pipeline_execution(
# name='string',
# clientRequestToken='string'
# )
# Inputs remediation action into DynamoDB for associated eventARN
# update_item_response = dynamno_db_client.update_item(
# TableName=config['default']['dynamodb_table_name'],
# Key={
# 'eventArn': {'S': event['arn']},
# 'service': {'S': event['service']},
# },
# ReturnValues= 'ALL_NEW',
# ReturnConsumedCapacity='INDEXES',
# UpdateExpression='SET remediationActionStatus = :updatedRemediationActionStatus, remediationActionTimestamp = :updatedRemediationActionTimestamp',
# ConditionExpression = "remediationActionStatus = :remediationActionStatus",
# ## Conditional for status code = open and failureNotificationStatus and failureNotificationTimestamp
# ExpressionAttributeValues={
# ":remediationActionStatus": {'S': 'N/A'},
# ":updatedRemediationActionStatus": {'S': 'Triggered'},
# ":updatedRemediationActionTimestamp": {'S': str(time.time())},
# },
# )
#remediate_SERVICE(detect_service_failures()[1])
To setup the tool, you can leverage the CloudFormation template below. That said after initial setup, setup of the configuration file is still required.
AWSTemplateFormatVersion: "2010-09-09"
Description: Setup for AWS Service Health Check Tool
Parameters:
DynamoDBTableNameParameter:
Description: Name of state tracking table for AWS Service Health Check Lambda
Type: String
Default: AWS-Failure-Events-State-Table
TagTablePurpose:
Description: Purpose tag for table
Type: String
Default: Table is used to track the state of AWS service level failures
PlatinumSNSTopicID:
Description: Name for the platinum SNS topic that will be created for platinum service outages
Type: String
Default: Platinum-AWS-Failure-SNS
GoldSNSTopicID:
Description: Name for the gold SNS topic that will be created for gold service outages
Type: String
Default: Gold-AWS-Failure-SNS
SilverSNSTopicID:
Description: Name for the silver SNS topic that will be created for silver service outages
Type: String
Default: Silver-AWS-Failure-SNS
PlatinumSubscriberEmail:
Description: Email address for platinum subscribers that will be subscribed to platinum topic. (One Only)
Type: String
Default: [email protected]
GoldSubscriberEmail:
Description: Email address for gold subscribers that will be subscribed to gold topic. (One Only)
Type: String
Default: [email protected]
SilverSubscriberEmail:
Description: Email address for silver subscribers that will be subscribed to silver topic. (One Only)
Type: String
Default: [email protected]
# Used to change the order that the parameters are presented in
Metadata:
AWS::CloudFormation::Interface:
ParameterGroups:
-
Label:
default: "DynamoDB Configuration"
Parameters:
- DynamoDBTableNameParameter
- TagTablePurpose
-
Label:
default: "SNS Topic Setup"
Parameters:
- PlatinumSNSTopicID
- GoldSNSTopicID
- SilverSNSTopicID
-
Label:
default: "SNS Subscriber Setup"
Parameters:
- PlatinumSubscriberEmail
- GoldSubscriberEmail
- SilverSubscriberEmail
Resources:
##### SNS Topic / Subscriber Setup #####
PlatinumSubscriptionTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: !Ref PlatinumSNSTopicID
PlatinumSubscription:
Type: AWS::SNS::Subscription
Properties:
Endpoint: !Ref PlatinumSubscriberEmail
Protocol: email
TopicArn: !Ref PlatinumSubscriptionTopic
GoldSubscriptionTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: !Ref GoldSNSTopicID
GoldSubscription:
Type: AWS::SNS::Subscription
Properties:
Endpoint: !Ref GoldSubscriberEmail
Protocol: email
TopicArn: !Ref GoldSubscriptionTopic
SilverSubscriptionTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: !Ref SilverSNSTopicID
SilverSubscription:
Type: AWS::SNS::Subscription
Properties:
Endpoint: !Ref SilverSubscriberEmail
Protocol: email
TopicArn: !Ref SilverSubscriptionTopic
#############################################################
##### DynamoDB State Tracking DB Setup #####
AWSFailureEventsStateTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
-
AttributeName: "eventArn"
AttributeType: "S"
-
AttributeName: "service"
AttributeType: "S"
KeySchema:
-
AttributeName: "eventArn"
KeyType: "HASH"
-
AttributeName: "service"
KeyType: "RANGE"
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
TableName: !Ref DynamoDBTableNameParameter
Tags:
- Key: "Purpose"
Value: !Ref TagTablePurpose
Outputs:
region:
Description: Region in which stack was deployed to and to be populated in Lambda config file
Value: !Ref "AWS::Region"
dynamodbTableName:
Description: DynamoDB table created to track state for service failures and value to be populated in config file
Value: !Ref AWSFailureEventsStateTable
platinumSnsArn:
Description: ARN of Platinum SNS Topic to be passed into Lambda Config File
Value: !Ref PlatinumSubscriptionTopic
goldSnsArn:
Description: ARN of Gold SNS Topic to be passed into Lambda Config File
Value: !Ref GoldSubscriptionTopic
silverSnsArn:
Description: ARN of Silver SNS Topic to be passed into Lambda Config File
Value: !Ref SilverSubscriptionTopic
The stack should provision all resources necessary to deploy the AWS Service Health Check Lambda as well as necessary output values that can be inputted into the lambda configuration file.
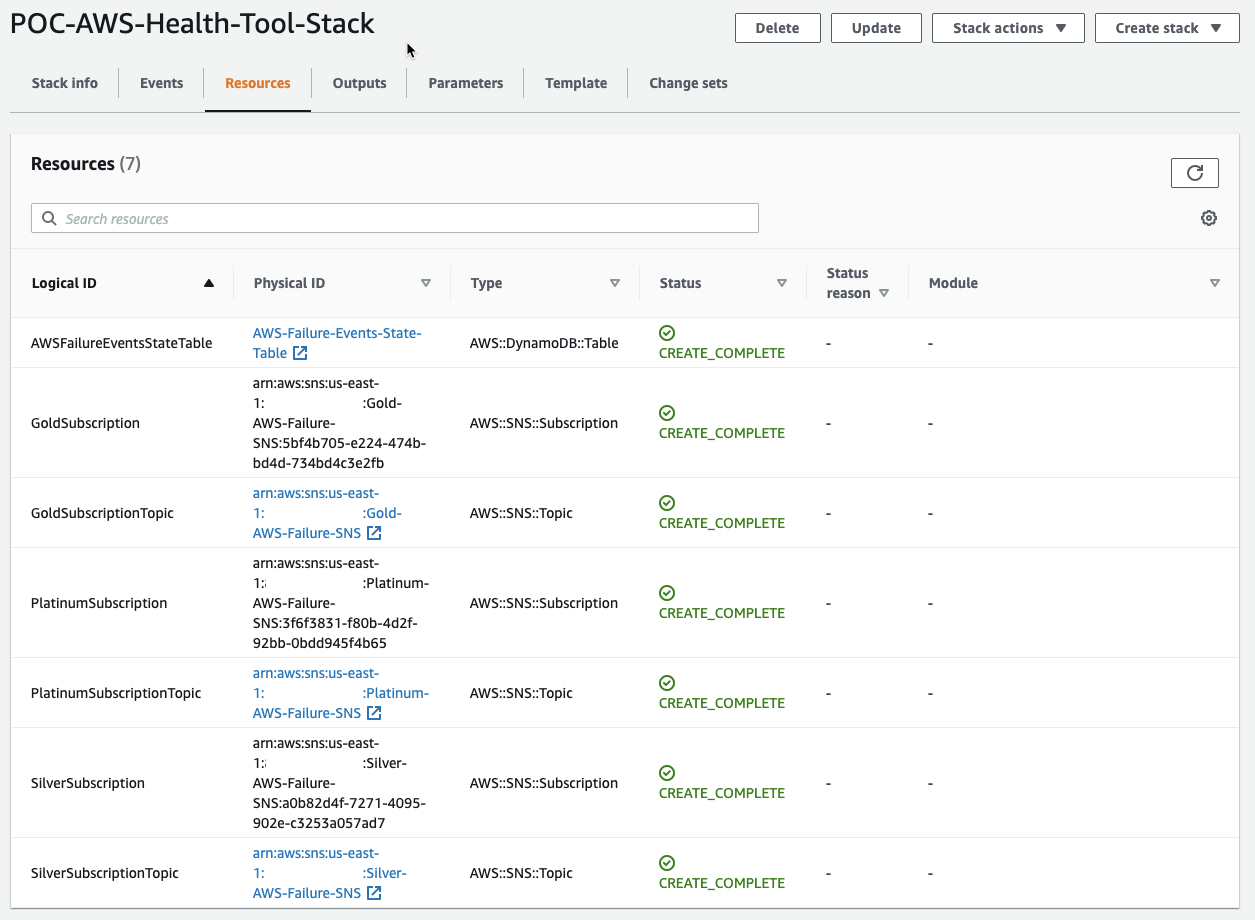
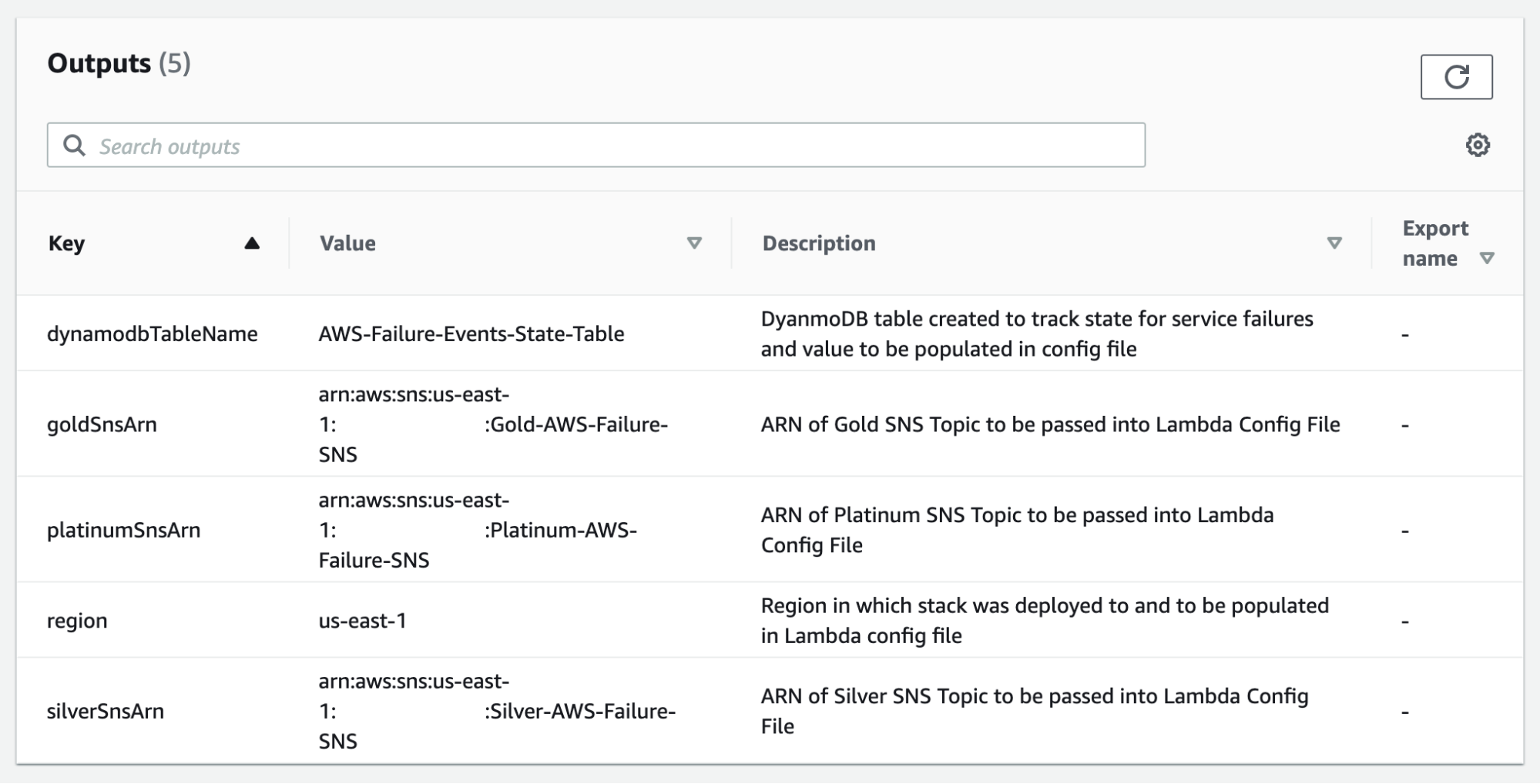
Region / Service Failure Takeaway
At the time of writing (January 2021), it should be noted how only a few AWS services natively support multi-region functionality. While there are a number of third party custom solutions that can be found online that leverage AWS services like Lambda, Step Functions, CodePipeline, and CloudFormation to quickly recover to additional regions, multi-region support is still somewhat in its infancy with most AWS services. When architecting for workloads that require a high level of resiliency, both AWS region, and service level failures need to be taken into account to ensure the workload can meet specified requirements.
Availability Zone / Resource Failure
After moving past region and service level failures, architecting and planning for availability zone and resource level failures appears to be much less complex. For the most part, this is true as many AWS services natively support monitoring, health checks, and other event-driven notifications to address such failures.
Below is a reference architecture that models a financial services trading platform API. We’ll touch on a few ways in which the architecture is designed with highly available components. Where highly available components were not able to be leveraged, we’ll also discuss what resilience measures are in place to ensure the workload can withstand both an availability zone failure and resource level failure.
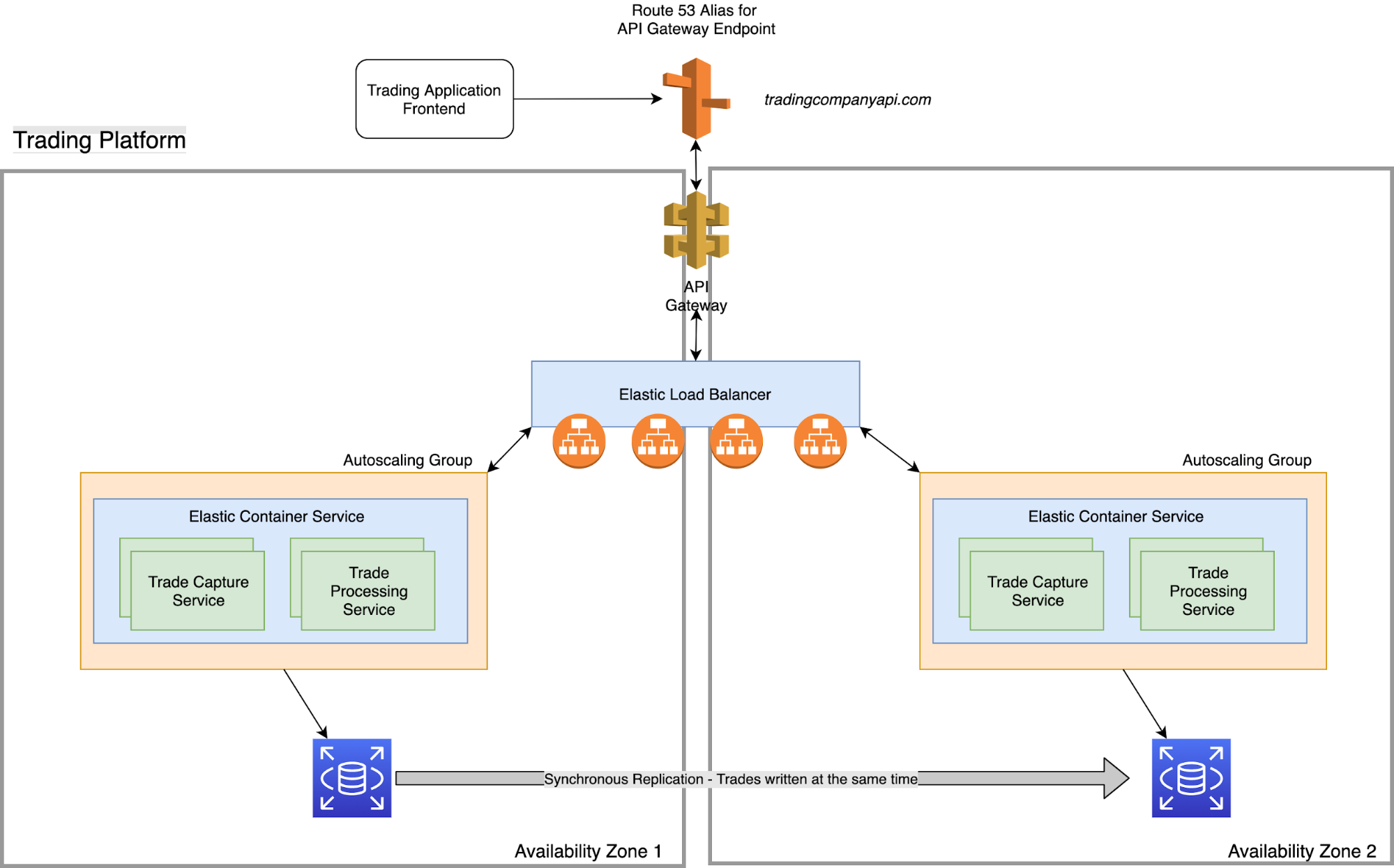
Highly Available Components:
- Multi-AZ Architecture
- API Gateway
- Elastic Load Balancer
- Route 53
- RDS (Multi-AZ)
- Autoscaling Group
Non-Highly Available Components:
- ECS Containers
AWS CloudWatch
As indicated above, the largest point of failure with this infrastructure is the individual ECS containers. With the help of CloudWatch, ECS will be automatically monitored for any resource level failure via the ECS task definition paired with the autoscaling groups. That should allow for container failure with automated recovery.
ELB / Route 53 Health Checks
There is an additional level of resiliency with the ELBs attached to the ECS containers. The ECS containers are specified within the target group for the ELB and a health check would be configured to constantly ensure that the container is responding and is healthy. In the event that a container were to go down, the ELB would stop sending traffic to that container until a healthy container was brought up and passed subsequent health checks from the ELB.
A similar configuration can be deployed with Route 53. In this case, we are using API Gateway which is a highly available service so it is not applicable. In the event that the containers in Availability Zone 1 and 2 were not responding properly, Route 53 could determine that from failed health checks and redirect traffic to an entirely different AZ or region.
Multi-AZ RDS
To round things off, the RDS database has been configured in a Multi-AZ deployment with synchronous replication to both AZs with automated failover. If AZ 1 were to experience any sort of availability issue, AZ 2’s standby replica would assume the primary DB role and handle all traffic going forward.
Availability Zone / Resource Failure Takeaway
Many of AWS’s services are both mature and resilient enough to offer native functionality that allows for handling both AZ and resource level failures with ease. With proper architecture principles by following AWS’s Well Architected Framework, AZ and resource failures should not pose a large threat to organizations of any size.
Conclusion
AWS and cloud computing as a whole, has forever changed the way IT professionals architect workloads. Among the most appealing features of migrating workloads to AWS is the enhanced resiliency and availability that comes with the shared responsibility model. That said, many often forget about AWS’s half of the shared responsibility model and the accountability they bear for keeping both the control and data plane up for the services they provide. It’s not a matter of if AWS will experience an outage, but rather when, as even the best of the best are not immune to failure. AWS’s CTO Werner Vogels said it best by stating,
“Everything fails, all the time”.
When the time of failure does come and it triggers a DR event, remember that with proper planning, monitoring, and alerting, the actual execution to resolve said DR event does not need to be and should not be disastrous in nature.
Vertical Relevance understands the disaster recovery requirements that large financial services institutions have. If you have critical applications that have specialized disaster recovery requirements, contact us today.
All source code from this blog can be located here.
