Overview
As modern systems increasingly tend toward distributed, complex workflows, resiliency becomes an ever-important topic. These workflows are often riddled with unknown pain points and failure conditions that, should they remain unnoticed, might cause unexpected and disastrous outages, with monetary consequences sure to follow. To avoid such outcomes, we need a more proactive approach – which is where resiliency testing and gamedays come in.
Resiliency testing allows organizations to see how their own systems react to fault injection; we purposely stress parts of a system to observe how the rest of it reacts. This approach allows us to preemptively identify pain points and plan around them. However, effective resiliency testing demands a large amount of engineering effort and knowhow, often from across disparate and siloed teams that lack any knowledge sharing processes in place. And with the growing size and complexity of modern systems, resiliency testing becomes increasingly unmanageable. There are a multitude of different testing scenarios that, if done manually, are all but impossible to keep track of, maintain, and improve. In the chance that testing does occur, it is often limited in scope and frequency as teams simply do not have the resources available to conduct exhaustive testing. In sum, the key hurdles are: a lack of centralized, authoritative methodology and process, inability to scale and adopt organization wide, and an incomplete range of coverage.
To combat these issues, Vertical Relevance has developed the Experiment Generator solution, an automated and systematic approach to designing and generating experiments. The Experiment Generator provides a centralized, clearly defined process for experiment creation with reusability and ease of use in mind. We take a modular approach such that once an experiment is designed, it can be reused across different application teams; each application team can access the full scope of experiments in the generator. Application teams need only provide parameter configurations for their specific app, which they would know best. The effort of structuring and formatting experiments is also fully automated, making the Generator simple to use.
Aside from the boon of automation, implementing our generator helps promote a stronger DevOps culture. Centralizing the methodology and making it more approachable breaks down knowledge silos and allows application teams to take a more holistic and integrated role in the resiliency process, and that without having to become resiliency experts themselves. Implementing the Experiment Generator allows organizations to clearly define a process and explicitly spell out everyone’s role, creating an environment for seamless teamwork and easier organization wide adoption.
Once organizations take this step, resiliency testing becomes much easier and paves the way to healthier and less failure prone systems. For executing experiments, see our Experiment Broker solution. For the next step in the resiliency journey, see our Gameday solution.
Prescriptive Guidance
Before diving into our Experiment Generator Solution, it is important to acknowledge the following terminology.
Definitions
- Chaos Toolkit – An open-source chaos engineering framework that enables conducting resiliency testing through code-based approaches.
- Actions – Functions or operations within the Chaos Toolkit framework that are responsible for changing the state of a system intentionally, such as injecting faults or introducing failures.
- Fault Injection – The deliberate and controlled process of introducing failures or faults into a system to observe and test how the system responds under these conditions.
- Probes – Functions within the Chaos Toolkit framework that monitor and report on the state of a system without making any changes to it. Probes are used to collect data and observations during experiments.
- Experiments – In the context of the Chaos Toolkit, experiments refer to a predefined and structured pattern for testing specific failure scenarios against an application or system.
- Method – Within the Chaos Toolkit experiment template, the “Method” represents a sequence of actions and probes that constitute a given experiment. It outlines the steps that the experiment will follow during execution.
- Steady state hypothesis – The baseline or expected state against which an experiment is conducted within the Chaos Toolkit. The steady state hypothesis is specific to the application or system being tested and serves as a reference point for measuring the impact of introduced faults or failures.
The following is terminology specific to Vertical Relevance’s Experiment Generator solution:
- Package – a directory containing python modules that define the action and probe functions
- Scenario – refers to the method section plus method specific configurations of an experiment. We use it to modularize our experiments
- Target application (configuration) – refers to the steady state hypothesis and any application specific configurations
- Experiment title – consists of Target Application-Scenario. The title formulates an experiment
Best Practices / Design Principals
Experiment Pipeline
Experiment generator, as the name implies, generates experiments. It does not execute them. For execution, Vertical Relevance recommends implementing the experiment pipeline and broker. However, the experiment generator is fully decoupled and runs asynchronously to the experiment broker. Indeed, we advise treating experiment generation and execution as separate processes, allowing for simpler operation and maintenance of the solution.
Modular Design
A core design principle of the Experiment Generator is the goal of minimizing duplicate efforts. To achieve this, Vertical Relevance takes a modular approach to experiment design. The generator divides an experiment into two fundamental parts – the target application and the scenario. Once an engineer from the resiliency team designs an experiment, it can be used by multiple (target) applications without having to redesign and revalidate everything. Further, application configurations overwrite scenario configurations, allowing teams to customize and overwrite anything they might need to change. In this way, we avoid duplicate efforts in experiment design.
SRE and DevOps Integration
Vertical Relevance strongly recommends following Vertical Relevance’s resiliency framework (see here). In our Resiliency Framework, our goal is to minimize the risk and impact of failure. The process involves rigorous architectural review to identify potential pain points, identification of non-functional requirements such as RTO (recovery time objective) and RPO (recovery point objective), and implementation of a testing framework such as FMEA (Failure Mode Effect and Analysis). Once these steps are taken, we have a direction for our resiliency journey and can design and execute experiments that will produce fruitful results.
For DevOps integration, we recommend keeping the following core principles in mind: automate to minimize toil, promote a culture of communication and collaboration, and iterate to improve. Ideally, application teams, those most knowledgeable about the ins and outs of an app, own their app specific configurations. To encourage this, we’ve incorporated a CLI utility to make the generator easy to use. For the smoothest CI/CD, this CLI utility should be integrated directly into application pipelines in such a manner that with every change to the application, the experiment configurations will also regenerate. In this way, we minimize the downtime in which an experiment’s configurations are outdated. Further, incorporating the change process directly into a pipeline/GitOps flow ensures all updates are tracked, thereby providing a historical record of what configurations ran during which timeframes. In all, adopting these practices smooths the way to more frequent resiliency testing across disparate application teams.
In addition, the experiment generator is written fully as infrastructure as code with the use of AWS CDK. We recommend maintenance and updates to the generator continue in this manner. IaC is an industry standard with numerous benefits and AWS CDK simplifies the management of AWS resources.
Adoptable and Extendable Design
Experiment Generator clearly spells out each team’s roles and does away with any confusion regarding who’s responsible for what. Responsibilities are parceled out according to expertise. Teams can start doing what they need to do immediately while the generator handles combining everyone’s efforts together. This all smoothens the path to adopting and scaling the Experiment Generator at the organizational level.
Built in Security
With regard to security, the experiment broker is self-contained and does not need access to any resources not created along with it. Executing experiments is a different matter, but our solution is fully decoupled from that stage and does not need any additional permissions. We need only to manage access to the Generator. All entry is facilitated through API Gateway and we recommend managing access via IAM (Identity Access Management) policies, resource policies, and/or enforcing VPC endpoint policies.
Experiment Generator
Vertical Relevance’s Experiment Generator is a lightweight and fully serverless solution, allowing for efficient resource utilization. Access to the generator is managed through a Command Line Interface (CLI) utility, which is ideally integrated into a Continuous Integration/Continuous Deployment (CI/CD) pipeline. This seamless integration facilitates automated and scalable generation processes, enhancing the overall efficiency of the development workflow.
Components
- AWS API Gateway – Facilitates access to the routes necessary to build and generate experiments
- AWS Lambda – Executes logic behind each API route
- AWS DynamoDB – Storage for configuration items. We use a single table design
- AWS S3 – Storage for generated experiments
- AWS SSM Parameter Store – stores API Gateway URL for ease of reference
How it works
The solution follows as standard serverless architecture. An API gateway handles access, containing various routes while Lambda handles all the business logic and S3 and DynamoDB handle storage. We also use SSM Parameter Store to hold the API gateway URL such that the CLI utility can reference it on first use. Our CLI utility, which is ideally integrated inside application pipelines, aids in accessing the generator and has the advantage of handling inputs and outputs via YAML. Alternatively, we can access directly via API calls.
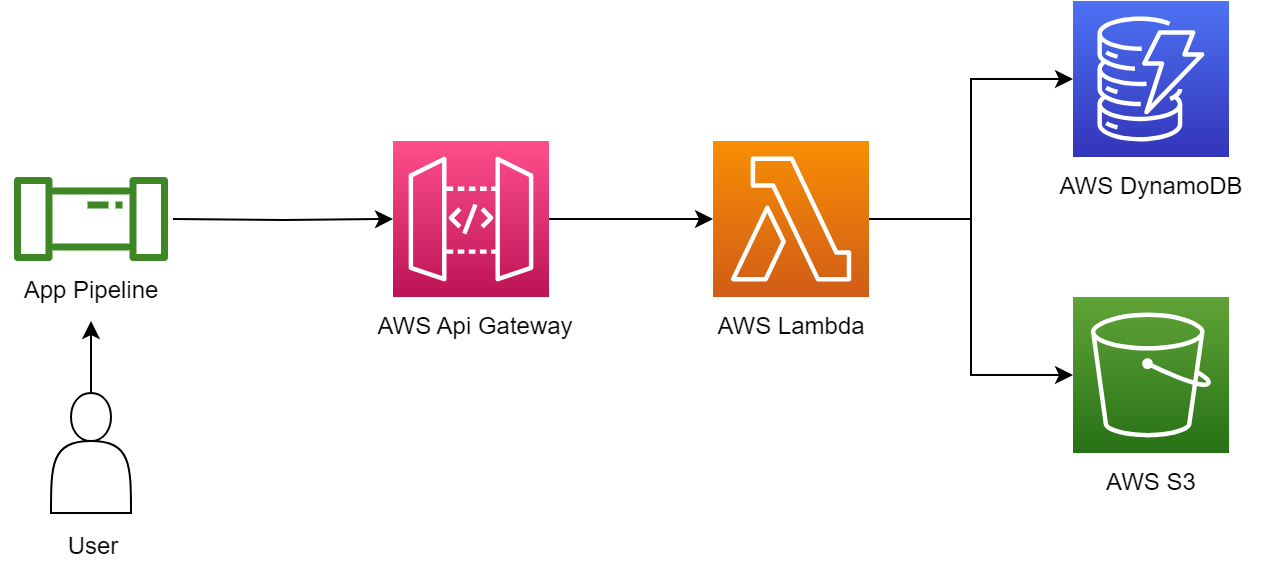
Figure-01
The following is an example step by step process flow of how a user would operate the experiment generator:
- Upload a zip file containing action and probe functions (such as chaosaws). The generator will parse through to extract all the necessary info it needs.
- Design resiliency testing scenarios (the method section of an experiment).
- To create a scenario, we need a sequence of actions and probe functions, ordered as they’re expected to run. Everything else the generator handles, the only requirement being all referenced functions must be in DynamoDB (uploaded in the previous step).
- For incorporating configurations like pauses, see samples.
- Onboard applications
- Create configurations and a steady state hypothesis unique to the app. Steady state must be a sequence of probes, as they are expected to run.
- App configurations take priority over scenario configurations; if there is conflict, app configurations overwrite.
- Run app init in the CLI utility to retrieve automated documentation of all available scenarios and the arguments they require.
- Generate experiments using scenario and application names i.e. app name-scenario name. This will be treated as the title and stored in S3 for future retrieval.
Experiment Broker in Action
Now that we’ve explored the Experiment Broker’s components, architecture diagram, and step-by-step process, let’s move on to an example where we’ll generate two experiments that apply stress to pod memory. First, create our experiment scenario as a YAML:
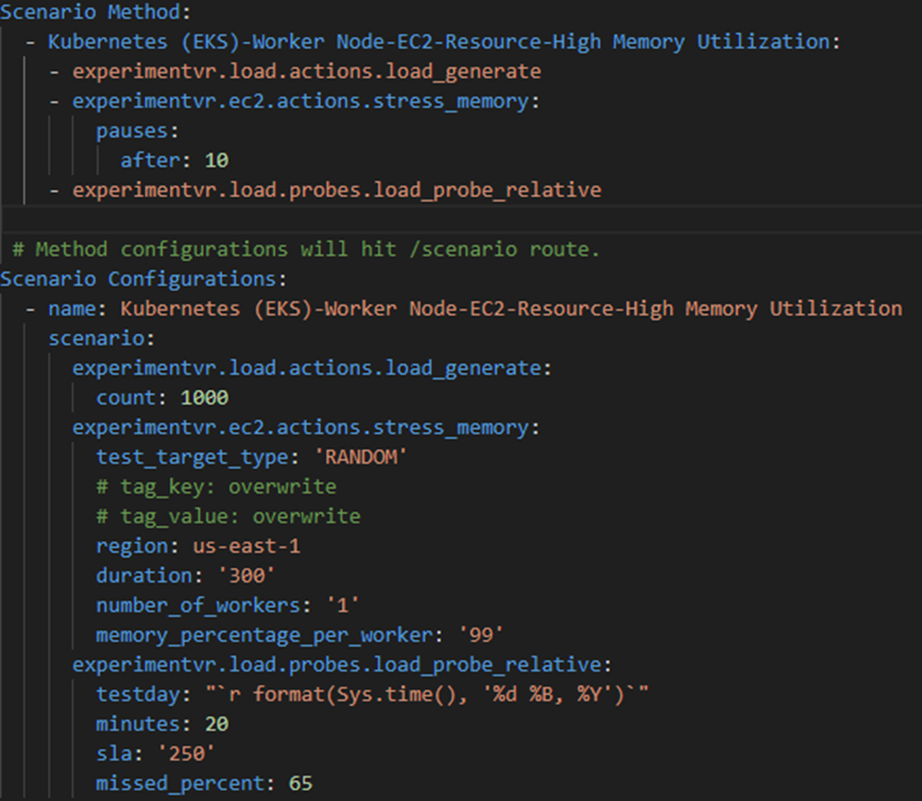
Figure-02
In the method section, we define a sequence of actions/probes to run. If we require configuration for pauses (or background process), it should be included here as in the example.
In the configuration section, we pass in the argument values we require.
Notice the name of the scenario “Kubernetes (EKS)-Worker Node-EC2-Resource-High Memory Utilization” – we will use this to identify the scenario during the generate step.
Next, use the CLI tool to create the experiment:

Figure-03
Now create the target application:
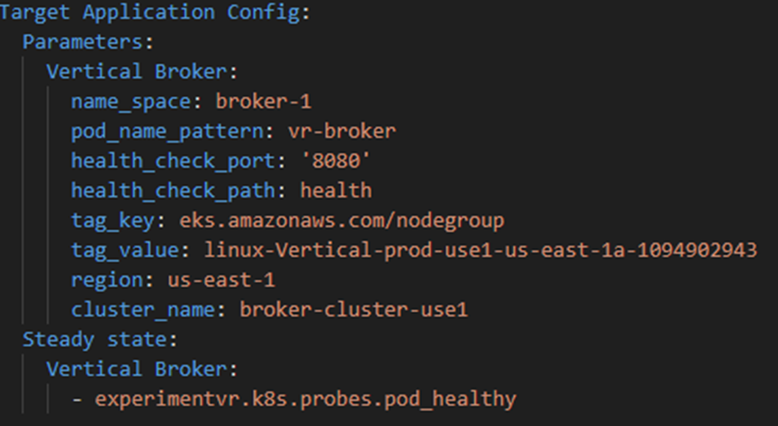
Figure-04
We set the name to of the app to Vertical Broker
And create:

Figure-05
Now we have a scenario and a target app; we can generate an experiment:

Figure-06
Below is the output:
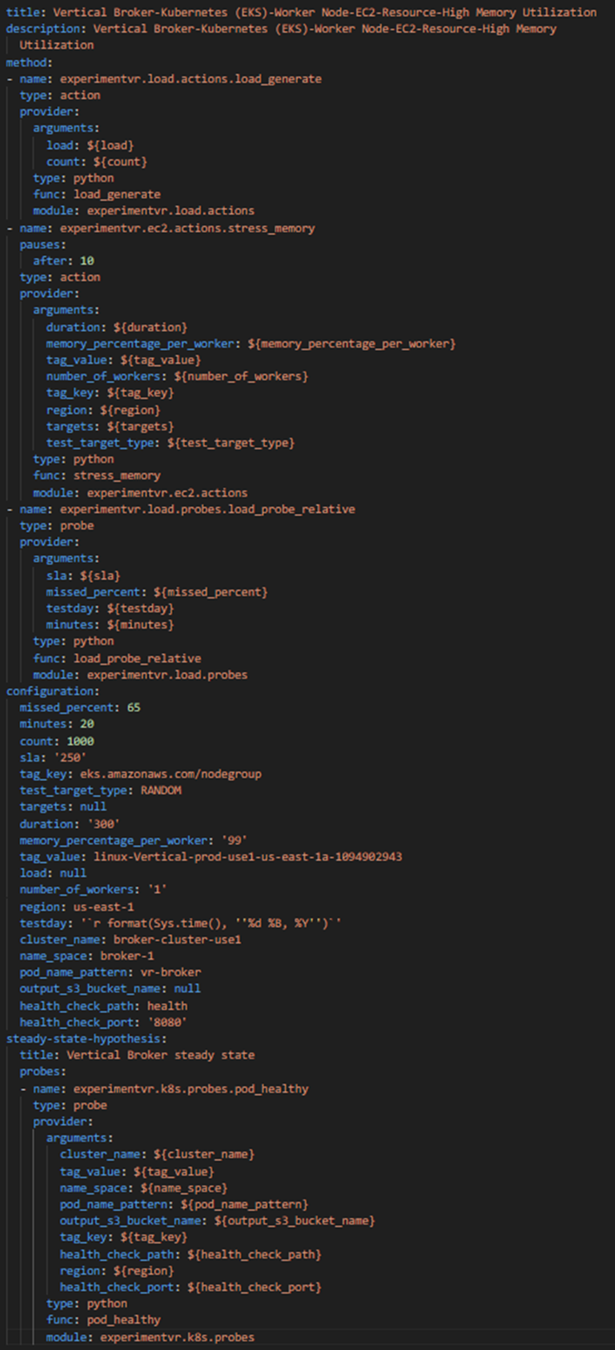
Figure-07
Now let’s onboard a second app with different configs:
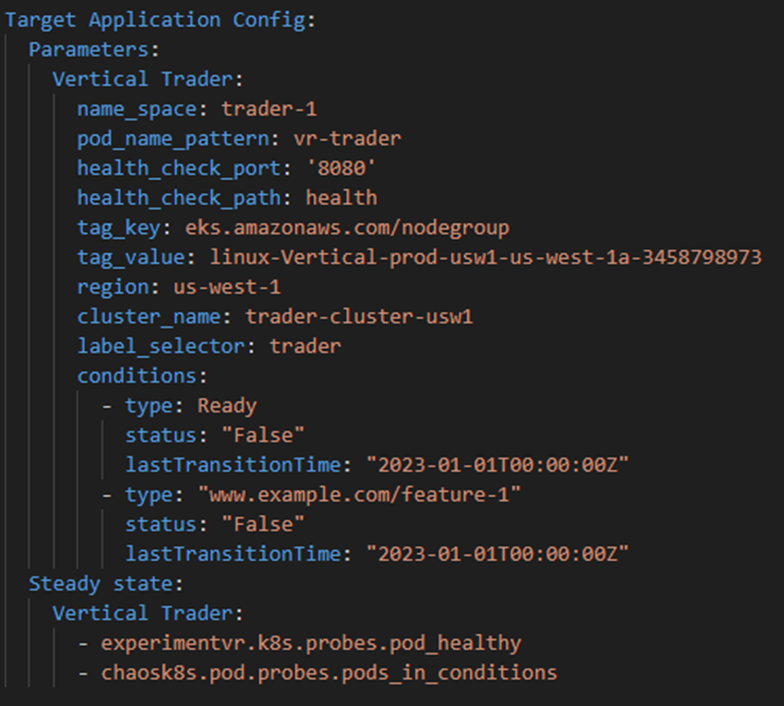
Figure-08
This one is for Vertical Trader. Note the differing configurations – name scheme and region unique to the app and a new steady state function.
Now create the app config:

Figure-09
And generate:

Figure-10
Note we merely needed to change the target app name.
Below is the output:
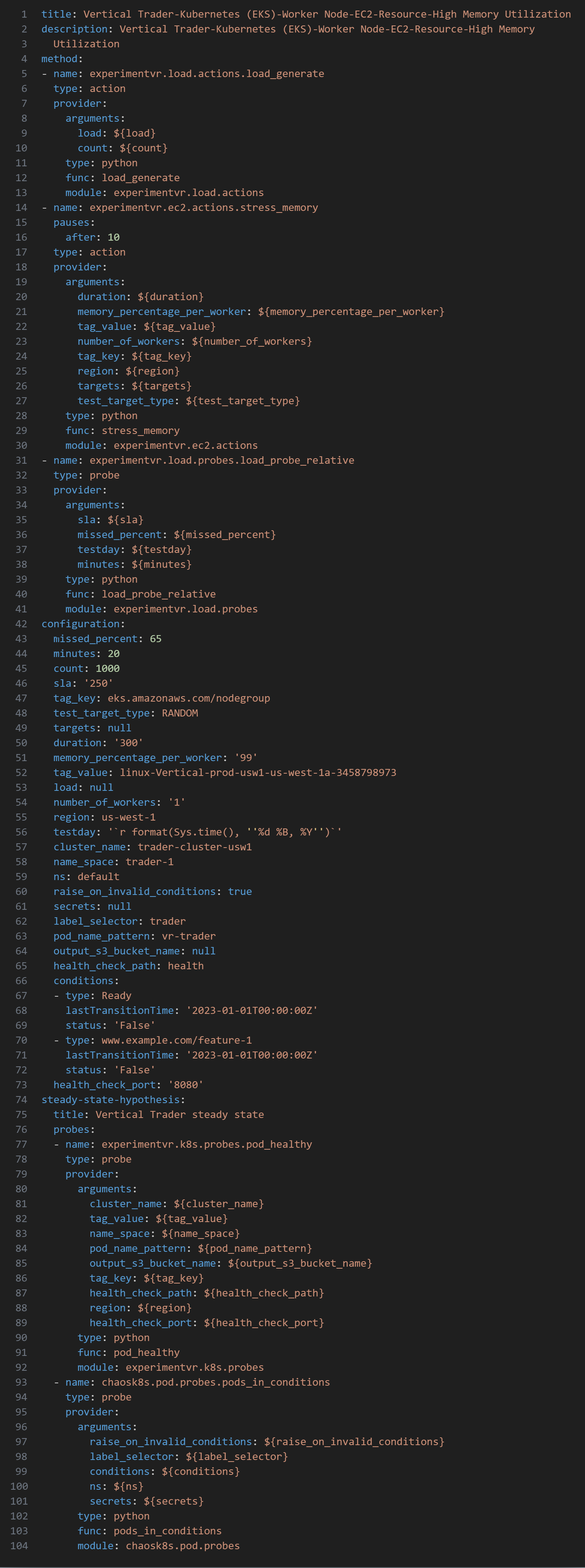
Figure-11
Blueprint
This section of the blueprint allows for the automated creation, design, and storage of Chaos ToolKit experiments.
- CDK Deployment – The AWS infrastructure and lambda code necessary to deploy and operate the Experiment Generator. Entirely serverless deployment
- CLI Tool – Contains the command line utility that simplifies access to the Experiment Generator API routes
Benefits
- Accelerates adoption and increases scope of resiliency testing: The Experiment Generator simplifies the process of conducting resiliency experiments, making it more accessible to teams and projects within an organization. This ease of use leads to a wider adoption of resiliency testing practices across different applications and services.
- Promotes more frequent testing and therefore safer systems: By automating and streamlining the experiment design and generation process, the Experiment Generator removes the difficulty in running and executing resiliency testing. This in turn encourages teams to test more frequently, teasing out vulnerabilities and bottlenecks, leading to safer and more reliable systems. Moreover, once experiment generation is streamlined, gamedays become significantly easier to execute.
- Breaks down knowledge silos and builds resiliency into team culture: The Experiment Generator brings the expertise of various teams together and simplifies and automates their role as much as possible. App owners own the configuration side while the SRE team owns the scenario side. The Experiment Generator handles stitching everything together, centralizing the SRE teams’ design efforts and multiplying them across app teams. Once app owners onboard their app, they have full access to all resiliency scenarios, allowing them to test with ease.
- Decoupled, self-contained and serverless approach simplifies implementation and maintenance: The Experiment Generator’s design makes implementation and maintenance easy – the infrastructure is AWS managed and the logic is decoupled from any other systems, allowing engineers to update it without worry of effecting external processes.
End Result
The Experiment Generator simplifies the resiliency testing process and accelerates its adoption, organization wide. Implementing the Experiment Generator brings an organization one step closer to its resiliency goals, both in relation to people and processes, in breaking down team barriers and automating as much as we can.
