About the Customer
The customer is one of the largest insurance companies in the United States. Their subsidiaries provide insurance, investment management, and other financial services to both retail and institutional customers throughout the United States and 40 other countries around the globe.
Key Challenge/Problem Statement
The primary challenges being encountered by the customer are a result of their reliance on manual processes related to sharing data between producers and consumers. This has led to both increased costs and data sprawl due to multiple copies of data sources and other data governance problems for the business.
State of Customer’s Business Prior to Engagement
The various data producer’s and consumer’s processes were riddled with manual tasks, multiple accounts, multiple copies of the same data, and other cumbersome data governance approaches. For instance, for NoSQL data stores, the client was overpaying because they had to pay for a higher tier of performance to be able to handle short-term spikes in reads and writes. To make matters worse, these costs were doubled due to multiple copies of this data in separate accounts to satisfy different consumers across the business. This, among other similar issues, resulted in unnecessary costs, inconsistent data handling processes, and general data sprawl.
Proposed Solution & Architecture
This data platform we delivered was designed to allow for click-button data ingestion, centralized data governance, and management of data during its lifecycle using an automated series of workflows. The platform uses multiple AWS services and data handling best practices along with ensuring appropriate company standards and analytics requirements are applied and maintained throughout. It is worth noting that there are future stages of this engagement planned to provide further enhancements to the platform.
The data platform was separated into four workflows that each span multiple accounts:
- Deployment
- Execution
- Permissions Data Warehouse
- Permissions Data Lake
Deployment
The deployment workflow is used to configure the environment to prepare to onboard data objects to the cloud. Its primary purpose is to provision the relevant AWS resources that are used by the later workflows (execution and permissions) to process each respective object.
The deployment workflow configures resources that span the Landing, Lake House, and Governance accounts. The diagram below illustrates the workflow steps that take place in each of the accounts.
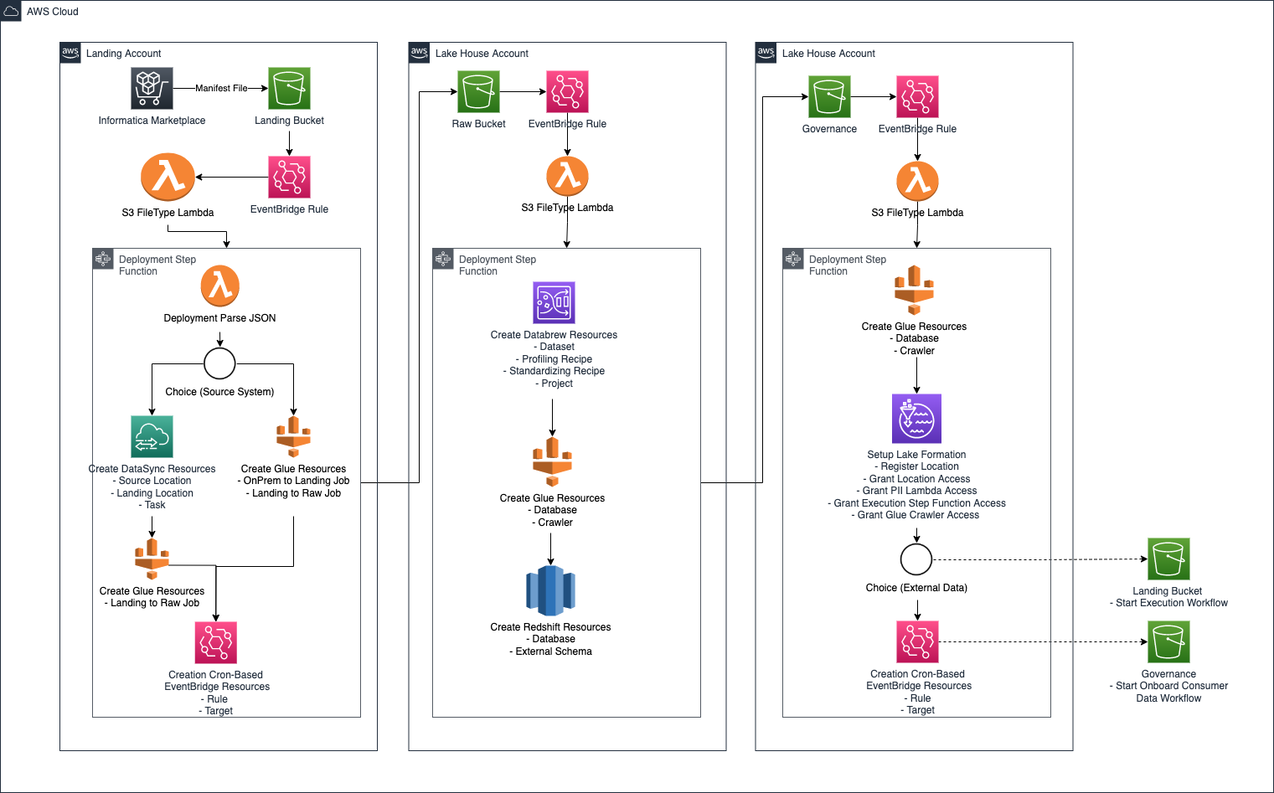
Figure-01
Execution
The execution workflow is used for both the first-time execution of a data object, along with its supplemental executions. The executions are triggered via a daily, cron-based Amazon EventBridge refresh cycle that kicks off a step function to process each data object.
As a future enhancement, this workflow will also identify and update data objects where there are deltas. In the meantime, an Amazon Athena-driven view is provided to address deltas as they arise.
The diagram below illustrates the workflow steps that take place in each of the accounts.
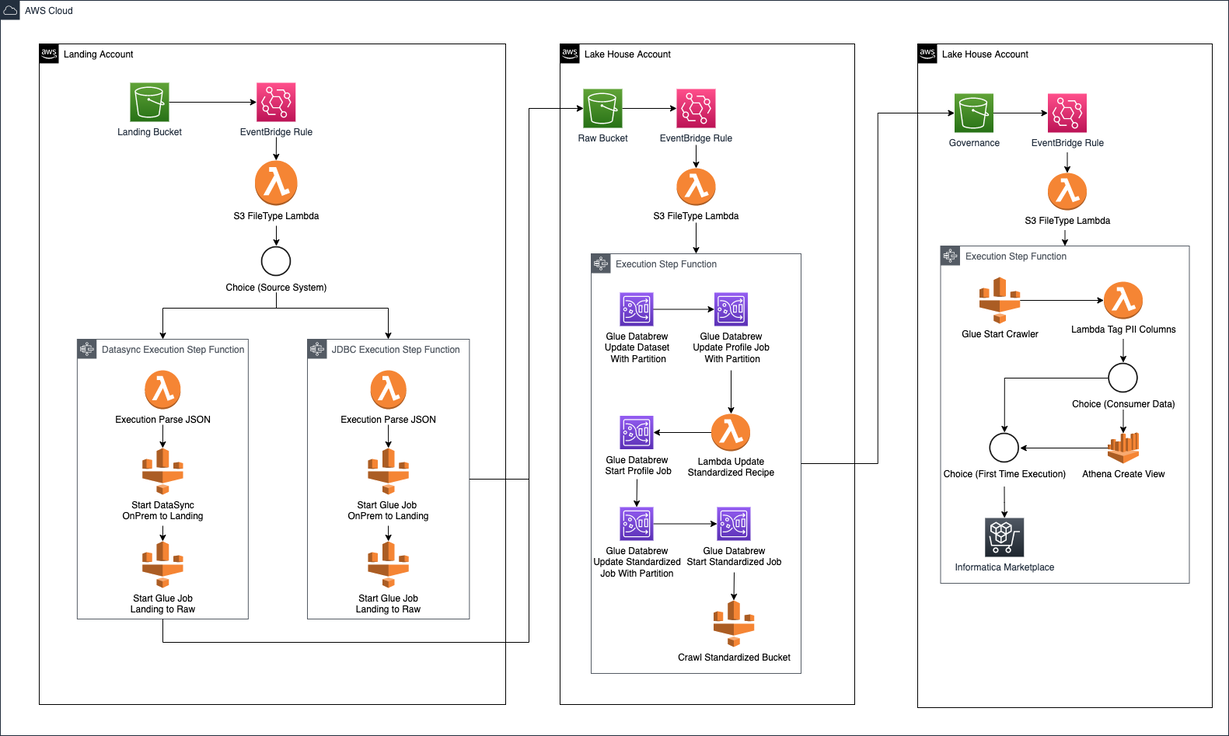
Figure-02
Permissions Data Warehouse
The permissions data warehouse workflow addresses the various complexities of permissions handling for the data warehouse features of the platform. The primary purpose of this workflow is to automate the alignment of the respective data producer and data consumer accounts for reliable permissions management. This is achieved by leveraging Amazon Redshift’s data sharing functinoality to provide the link between the respective accounts and allow for the proper data governance.
The diagram below illustrates the workflow steps that take place in each of the accounts.
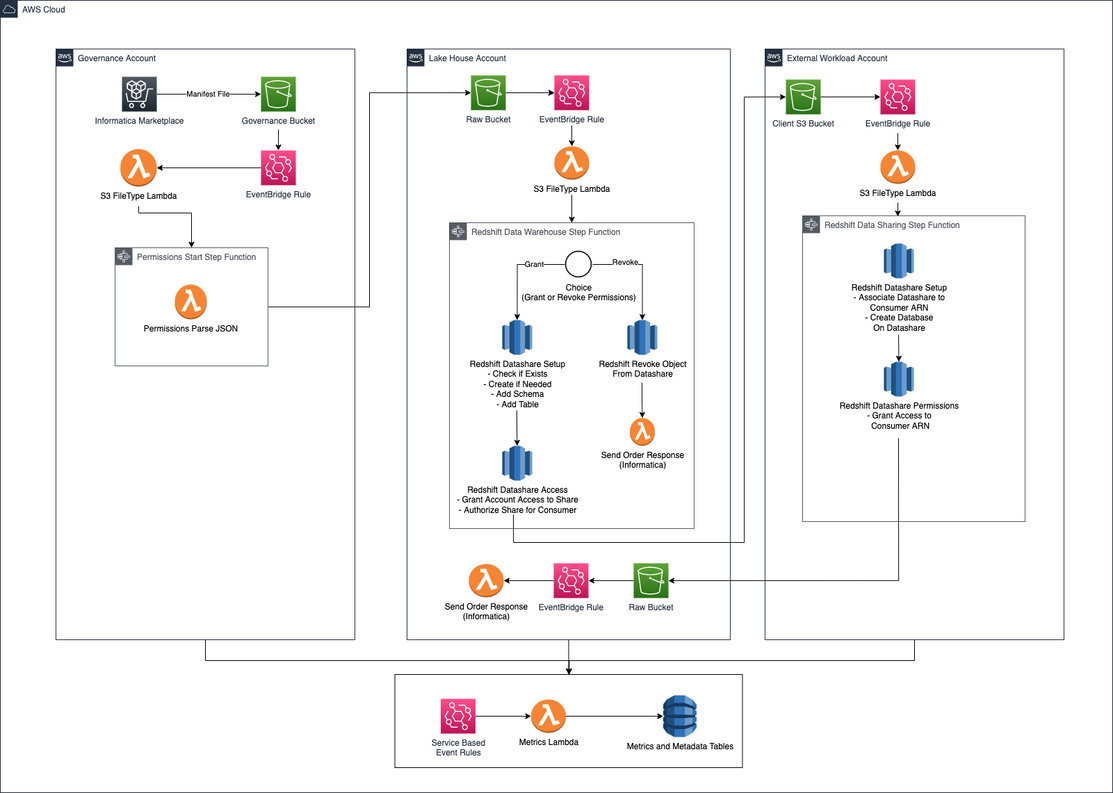
Figure-03
Permissions Data Lake
The permissions workflow for the data lake is used to handle the various complexities involved with maintaining a data lake. The primary purpose of this workflow is to keep many different types of accounts and their data objects in sync. This was accomplished by leveraging a step function that integrated with AWS Lake Formation to handle database sharing and cross-account permissions management.
The diagram below illustrates the workflow steps that take place in each of the accounts.
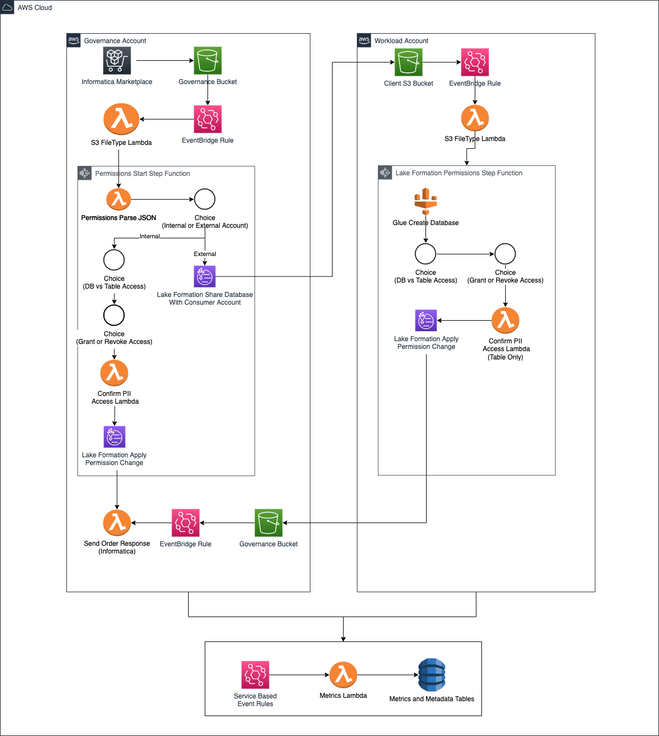
Figure-04
Metadata Management
As part of this solution there were multiple DynamoDB tables to assist with tracking the data, usage, costs, and requests that were performed during the automation of the workflows above. The purpose of each of these tables are as follows.
- Metrics – A table in each account to capture the actions performed by the various components of the workflows. These entries are primarily driven by Amazon EventBridge events to capture creation and actions of the various components when processing data.
- Cost Allocation – A combination of the python UUID library and a “job_id” capable tagging system. The cosr allocation DynamoDB tables in each account were used to trace the actions performed and allow cost allocation to be calculated for each of the client’s respective “cost centers”.
- State Management – Due to the complexity of the solution and its moving parts, there is also a set of DynamoDB tables to help assist with the automation and approval requirements of the platform. These tables performed duties such as associating secrets with their respective sources and tracking the execution details (such as date/time) for data sourcing items.
- Third party integration and order management – When processing an order submitted from the front-end catalog tool (Informatica) a few DynamoDB tables were used to track the manifest file contents and respective parameters used. These tables assisted with the information required by the product for the order system along with providing an integration method to pass the respective information to the platform.
AWS Services Used
AWS Infrastructure Scripting – CloudFormation
AWS Networking Services – VPC
AWS Management and Governance Services – CloudWatch, CloudTrail, Organizations
AWS Security, Identity, Compliance Services – IAM, Key Management Service
AWS Application Integration – Step Functions, Event Bridge
AWS Analytics – Lake Formation, Athena, Glue
AWS Databases – Redshift, DynamoDB
Third-party applications or solutions used
- Jenkins
- Jira
- Informatica
- OnPrem Data Sources
- Hadoop
- Denodo
Outcome Metrics
- Developed simple, “click-button” automation to create a scalable and adaptable platform
- Replaced multi-day manual processes with automation that performed the same tasks in a few hours at most
- Improved data security by removing human error from processes around data onboarding and governance
- Introduced automated PII detection and data standardization into the various workflows to meet regulatory requirements
Lessons Learned
- Redshift and False Positives – Watch out for false-positives when sending commands. Use the response Id to confirm the command actually processed. The initial “Success” response you receive from redshift might not be the “actual command(s) status”.
- SNS Topics and Filtering – For complex topics and subscription solutions, you can use subscription filters combined with message attributes to assist with getting the message to the right location. In this case to allow for the proper client consumer account to the correct message.
- Lake Formation Access Controls – When working with Lake Formation access controls, make sure to think through all the possible scenarios and access types that need to be accounted for. User vs Role, Column vs Table vs Database, Encryption and KMS keys, PII vs Non-PII data, flagging “rogue access”, etc.
Summary
The data platform delivered as part of this engagement provides multiple automation-driven workflows capable of handling data from multiple sources in a code-light solution. This platform is capable of scaling to accommodate the various steps of the data lifecycle along with tracking of all the steps involved including cost allocation, parameter capturing, and the providing of metadata required for integration of the client’s third party services.
